
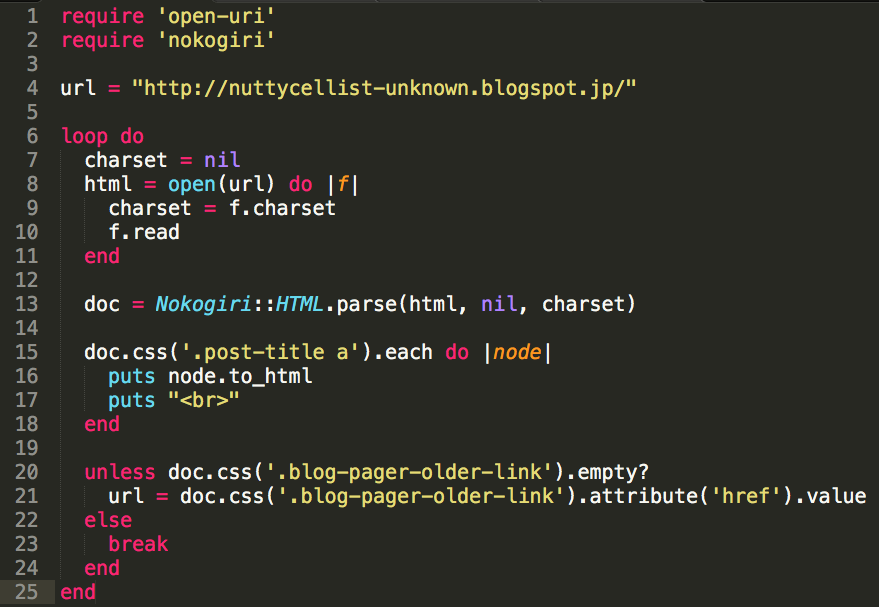
Suppose you wish to make a list of all the titles posted at a particular blog, then you write a program something like this:
require 'open-uri'
require 'nokogiri'
url = "http://nuttycellist-unknown.blogspot.jp/"
loop do
charset = nil
html = open(url) do |f|
charset = f.charset
f.read
end
doc = Nokogiri::HTML.parse(html, nil, charset)
doc.css('.post-title a').each do |node|
puts node.to_html
puts "<br>"
end
unless doc.css('.blog-pager-older-link').empty?
url = doc.css('.blog-pager-older-link').attribute('href').value
else
break
end
end


The CSS selectors should be determined depending on the html code employed on the site.
What you will get is an html file showing the titles.
<a href="http://nuttycellist-unknown.blogspot.jp/2017/09/arrival-of-fall-season.html">Arrival of fall season</a> <br> <a href="http://nuttycellist-unknown.blogspot.jp/2017/09/chicken-cooked-with-welsh-onion.html">Chicken cooked with welsh onion</a> <br> <a href="http://nuttycellist-unknown.blogspot.jp/2017/08/seventy-two-years-have-passed.html">Seventy two years have passed</a> <br> ...