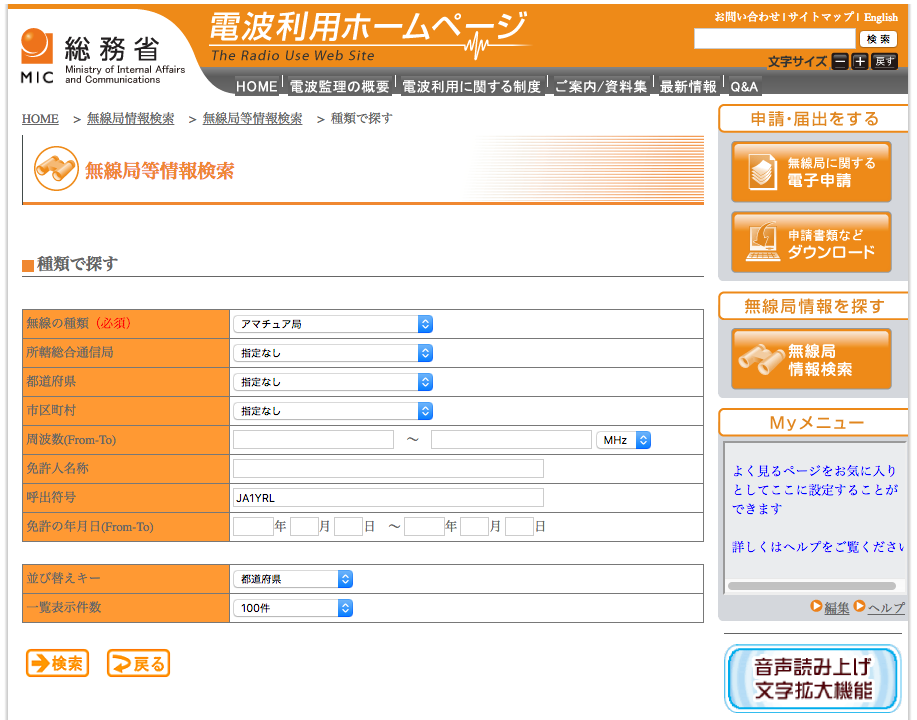
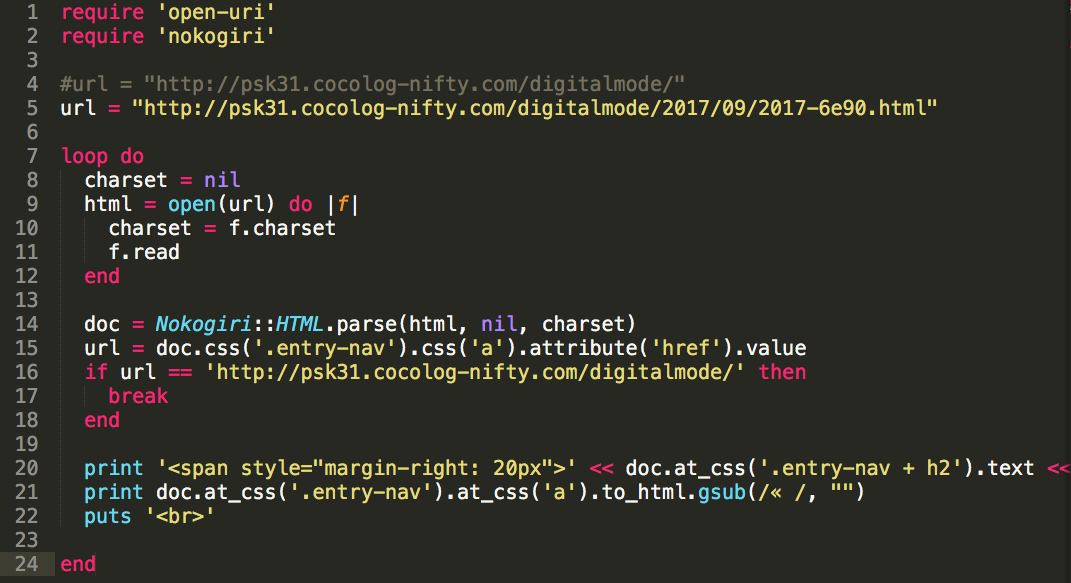
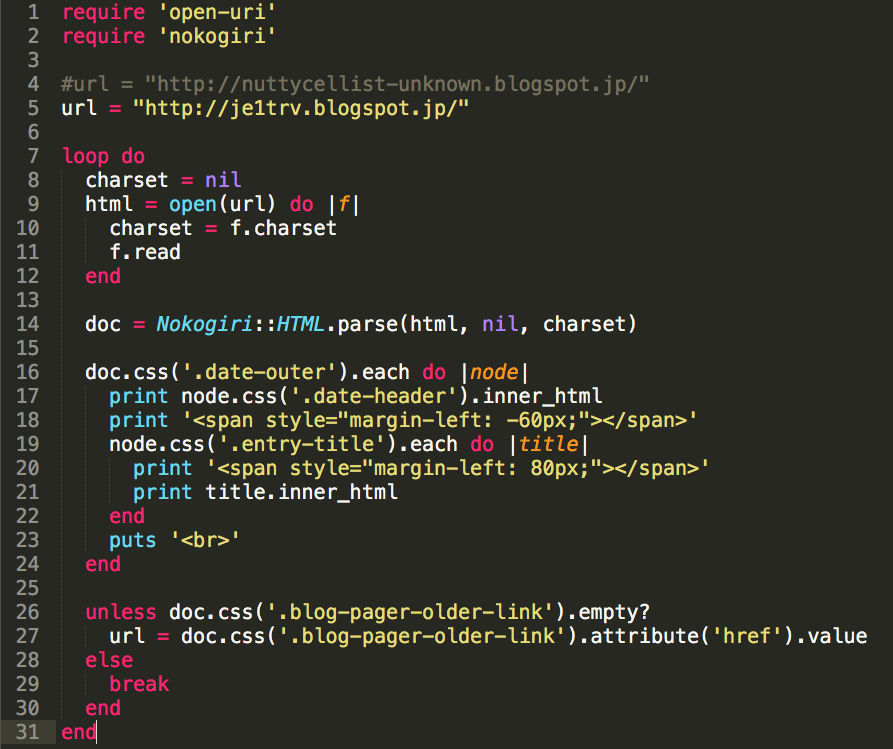
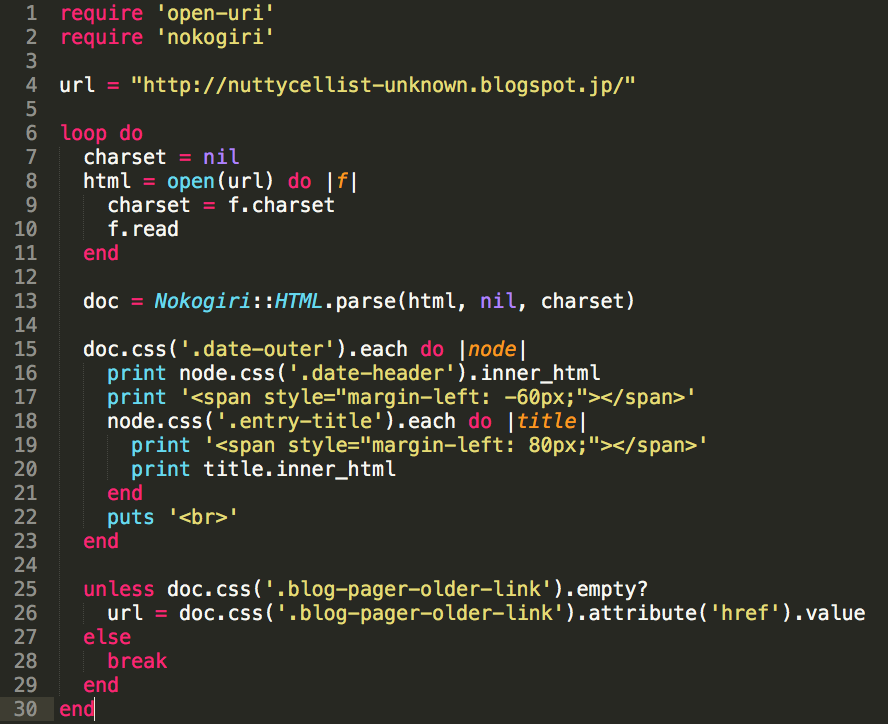
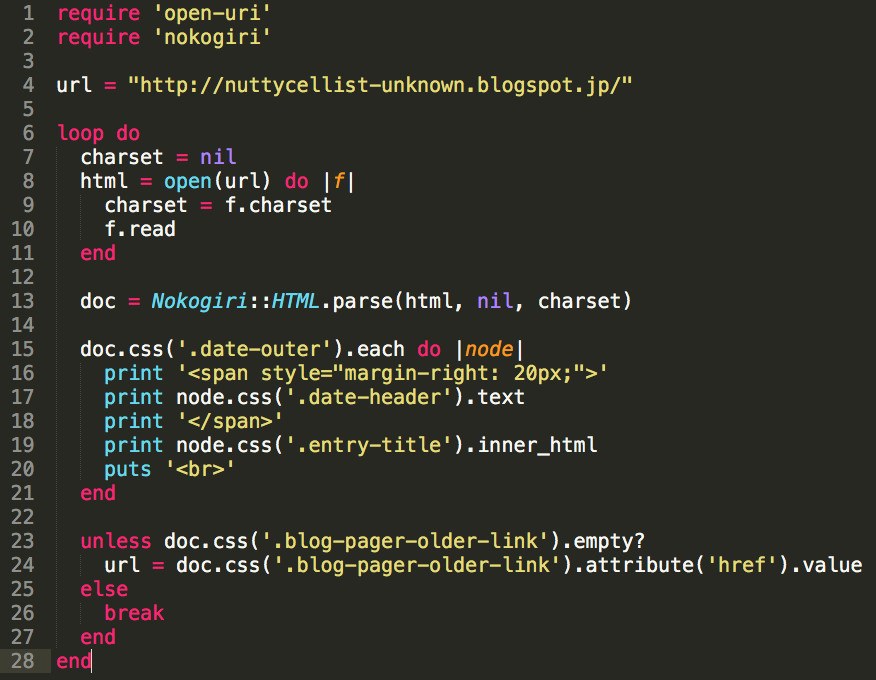
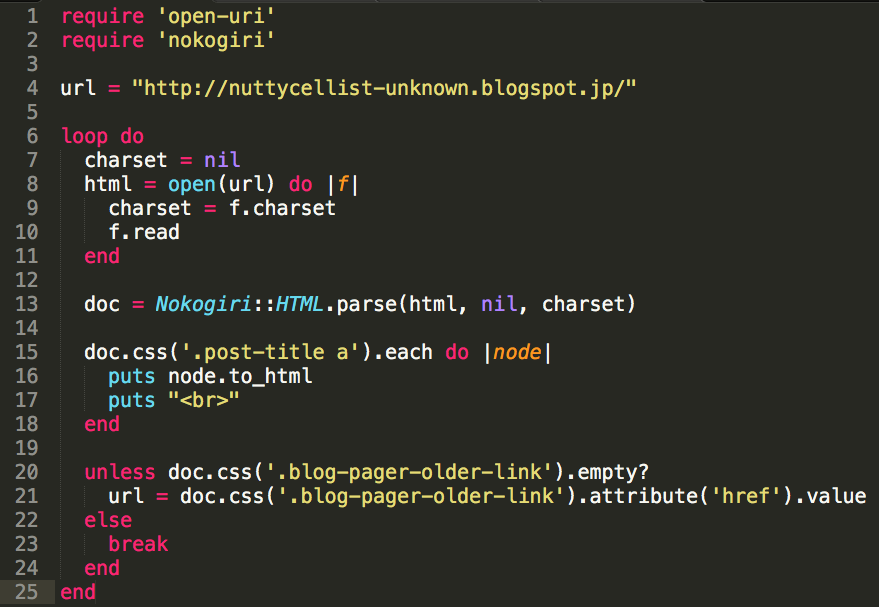
Suppose you have a file containing the list of the stations of which you wish to get the QTH.
JH2CMH JI4JGD JA5IVG JR2AWS JA4VPS JI3CJP 7K1CPT JH3HGI JA4MRL JH2FOR JE1TRV
You write a ruby program like this:
require 'mechanize'
agent = Mechanize.new
agent.user_agent = 'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)'
url = 'http://www.tele.soumu.go.jp/musen/SearchServlet?SK=2&DC=100&SC=1&pageID=3&CONFIRM=0&SelectID=1&SelectOW=01'
page = agent.get(url)
File.foreach('a1cc.txt') do | t |
print t.chomp << " "
next_page = page.form_with(:name => 'select_condition') do |form|
form.MA = t.chomp
end.submit
puts next_page.css('form[name="result"] td')[8].text.gsub(/[\n\t]/,"")
end
And you will get:
% ruby mechanize.rb JH2CMH 愛知県日進市 JI4JGD 岡山県井原市 JA5IVG 香川県高松市 JR2AWS 岐阜県高山市 JA4VPS 広島県廿日市市 JI3CJP 滋賀県近江八幡市 7K1CPT 茨城県かすみがうら市 JH3HGI 兵庫県赤穂郡上郡町 JA4MRL 岡山県岡山市南区 JH2FOR 愛知県あま市 JE1TRV 東京都町田市