
a, .-
aa, .- .-
aal, .- .- .-..
aalii, .- .- .-.. .. ..
(many lines deleted)
zythia, --.. -.-- - .... .. .-
zythum, --.. -.-- - .... ..- --
zyzomys, --.. -.-- --.. --- -- -.-- ...
zyzzogeton, --.. -.-- --.. --.. --- --. . - --- -.
This is a training sequence with 234,369 lines generated by a short Python program below.
Let’s see if we can decode the words with four characters.
Train on 4894 samples, validate on 100 samples
We have 4894+100 such words, so we randomly choose 100 words and put them aside so that they are only used for validation and not for training.
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= lstm_1 (LSTM) (None, 128) 67584 _________________________________________________________________ repeat_vector_1 (RepeatVecto (None, 4, 128) 0 _________________________________________________________________ lstm_2 (LSTM) (None, 4, 128) 131584 _________________________________________________________________ lstm_3 (LSTM) (None, 4, 128) 131584 _________________________________________________________________ lstm_4 (LSTM) (None, 4, 128) 131584 _________________________________________________________________ time_distributed_1 (TimeDist (None, 4, 27) 3483 ================================================================= Total params: 465,819 Trainable params: 465,819 Non-trainable params: 0
-.-. --- .--. .- copa copa -.- -.-- .- .... kyah kyah -... .-. .- . brae brae -. .- .-. -.- nark nark .--. .... --- .... phoh phob .- --.. --- -. azon auon -.-. --- ...- . cove cove -... .- .-. .. bari bari -- . .- -.- meak meak -- --- -. --. mong mong -- .- - . mate mate - .... .. .-. thir thir
Not bad?
Note that the decoding program has no morse code tables whatever.
from keras.models import Sequential
from keras import layers
import numpy as np
import matplotlib.pyplot as plt
class CharTable(object):
def __init__(self, chars):
self.chars = sorted(set(chars))
self.char_indices = dict((c, i) for i, c in enumerate(self.chars))
self.indices_char = dict((i, c) for i, c in enumerate(self.chars))
def encode(self, token, num_rows):
x = np.zeros((num_rows, len(self.chars)))
for i, c in enumerate(token):
x[i, self.char_indices] = 1
return x
def decode(self, x, calc_argmax=True):
if calc_argmax:
x = [x.argmax(axis=-1)]
return ''.join(self.indices_char[int(v)] for v in x)
def main():
word_len = 4
max_len_x = 4 * word_len + (word_len - 1)
max_len_y = word_len
input_list = []
output_list = []
fin = 'words_morse.txt'
with open(fin, 'r') as file:
for line in file.read().splitlines():
mylist = line.split(", ")
[word, morse] = mylist
morse = morse + ' ' * (max_len_x - len(morse))
if len(word) == word_len:
input_list.append(morse)
output_list.append(word)
chars_in = '-. '
chars_out = 'abcdefghijklmnopqrstuvwxyz '
ctable_in = CharTable(chars_in)
ctable_out = CharTable(chars_out)
x = np.zeros((len(input_list), max_len_x, len(chars_in)))
y = np.zeros((len(output_list), max_len_y, len(chars_out)))
for i, token in enumerate(input_list):
x[i] = ctable_in.encode(token, max_len_x)
for i, token in enumerate(output_list):
y[i] = ctable_out.encode(token, max_len_y)
indices = np.arange(len(y))
np.random.shuffle(indices)
x = x[indices]
y = y[indices]
m = len(x) - 100
(x_train, x_val) = x[:m], x[m:]
(y_train, y_val) = y[:m], y[m:]
hidden_size = 128
batch_size = 128
nlayers = 3
epochs = 100
model = Sequential()
model.add(layers.LSTM(hidden_size, input_shape=(max_len_x, len(chars_in))))
model.add(layers.RepeatVector(word_len))
for _ in range(nlayers):
model.add(layers.LSTM(hidden_size, return_sequences=True))
model.add(layers.TimeDistributed(layers.Dense(len(chars_out), activation='softmax')))
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
model.summary()
hist = model.fit(x_train, y_train, batch_size=batch_size,
epochs=epochs, verbose=2, validation_data=(x_val, y_val))
predict = model.predict_classes(x_val)
for i in range(len(x_val)):
print("".join([ctable_in.decode(code) for code in x_val[i]]),
"".join([ctable_out.decode(code) for code in y_val[i]]), end=" ")
for j in range(word_len):
print(ctable_out.indices_char[predict[i][j]], end="")
print()
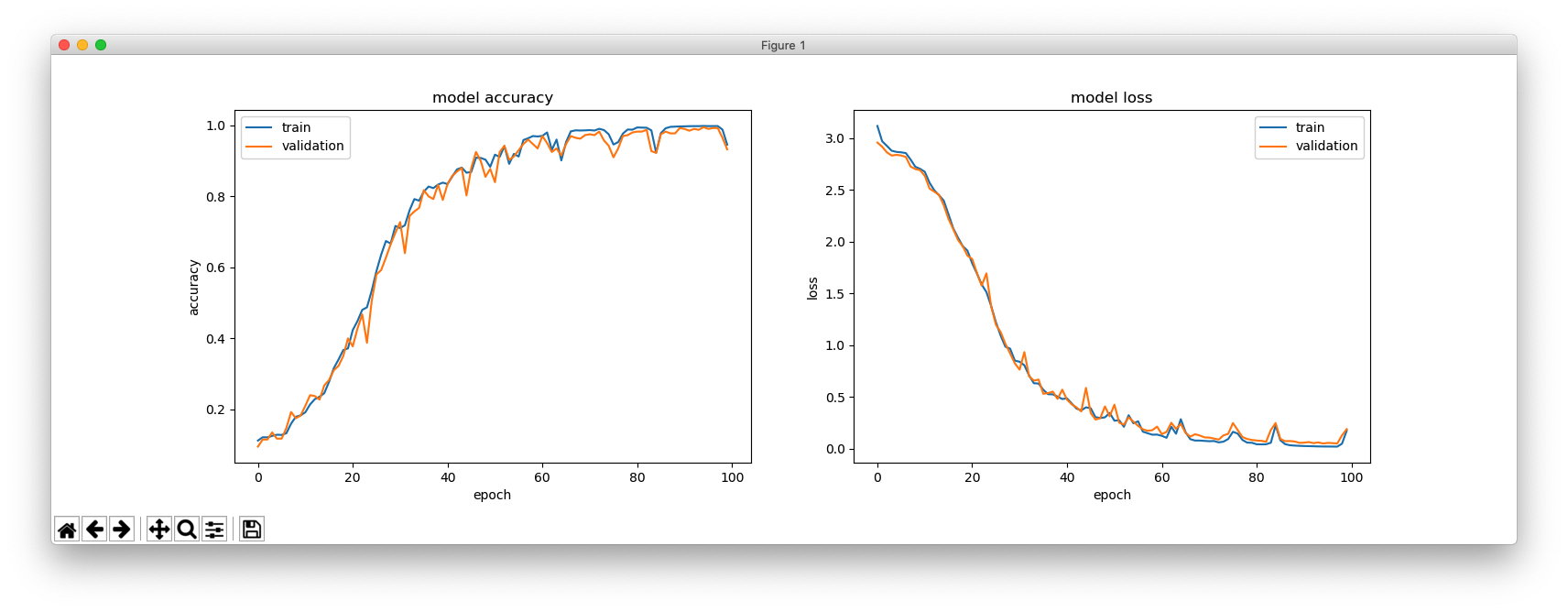
plt.figure(figsize=(16, 5))
plt.subplot(121)
plt.plot(hist.history['acc'])
plt.plot(hist.history['val_acc'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'validation'], loc='upper left')
plt.subplot(122)
plt.plot(hist.history['loss'])
plt.plot(hist.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'validation'], loc='upper right')
plt.show()
main()
The following program is to generate a training sequence. A morse code table is required only in this program.
import numpy as np
def morse_encode(word):
return " ".join([morse_dict[i]for i in " ".join(word).split()])
def data_gen():
fin = 'words_alpha.txt'
with open(fin, 'r') as file:
for word in file.read().lower().splitlines():
print(word, morse_encode(word), sep=", ")
return
alphabet = list("abcdefghijklmnopqrstuvwxyz")
values = ['.-', '-...', '-.-.', '-..', '.', '..-.', '--.', '....', '..', '.---', '-.-',
'.-..', '--', '-.', '---', '.--.', '--.-',
'.-.', '...', '-', '..-', '...-', '.--', '-..-', '-.--', '--..']
morse_dict = dict(zip(alphabet, values))
data_gen()