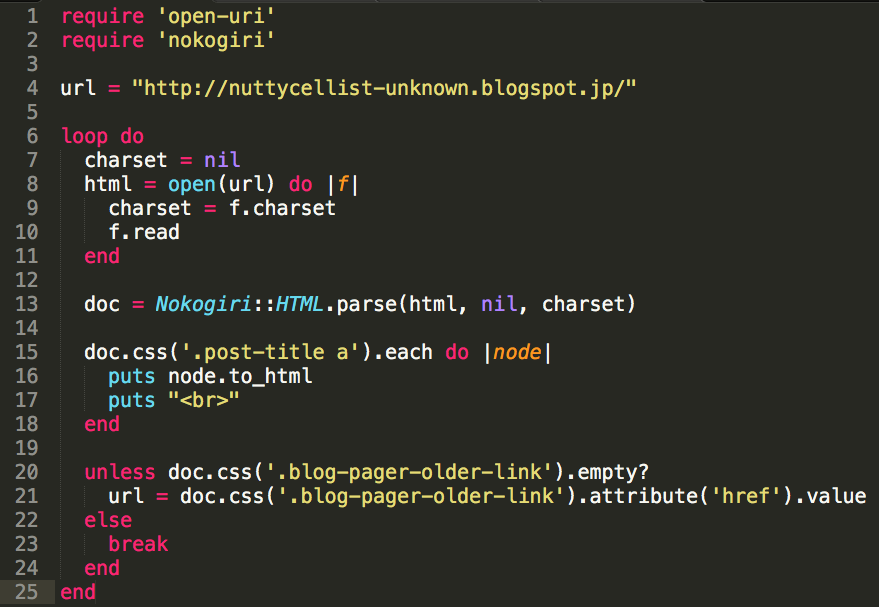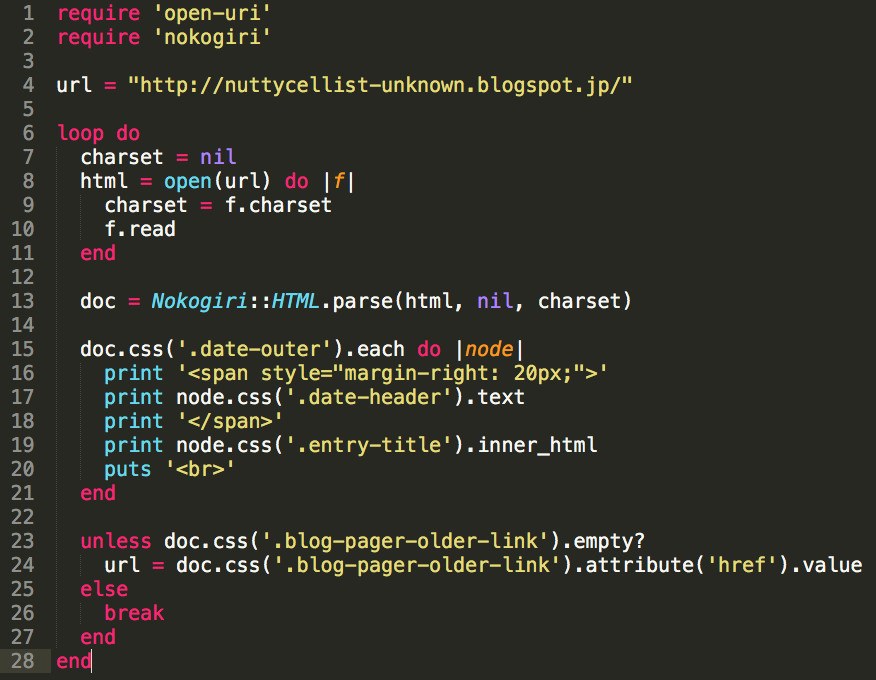
require 'open-uri'
require 'nokogiri'
url = "http://nuttycellist-unknown.blogspot.jp/"
loop do
charset = nil
html = open(url) do |f|
charset = f.charset
f.read
end
doc = Nokogiri::HTML.parse(html, nil, charset)
doc.css('.date-outer').each do |node|
print '<span style="margin-right: 20px;">'
print node.css('.date-header').text
print '</span>'
print node.css('.entry-title').inner_html
puts '<br>'
end
unless doc.css('.blog-pager-older-link').empty?
url = doc.css('.blog-pager-older-link').attribute('href').value
else
break
end
end
Somewhat improved. The link is here.

If there are multiple posts in a day, the titles are not separated properly with the short code shown here.