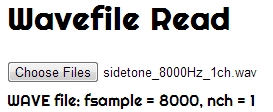
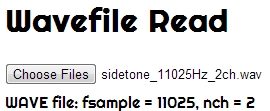
Here is a new page with a javascript that reads the header of a wave file to get fsample and nch. Changed lines are highlighted in the code below. I know this is a clumsy job and contains a minor bug, but it is workable.
Just for your information, if you double click anywhere on the code, the entire code is selected, and you can copy them all with a simple Ctrl/Cmd-C. Code selection works normally with your mouse.
You can download (right-click on the link) the following files to your PC to check my new page.
<!doctype html>
<head>
<meta charset="utf-8" />
<title>Wavefile Read 2</title>
<script src="Three.js"></script>
<script src="flotr2.min.js"></script>
<link href='http://fonts.googleapis.com/css?family=Righteous' rel='stylesheet' type='text/css'>
<style type="text/css">
div#canvas-frame{
border: none;
cursor: pointer;
width: 610px;
height: 300px;
background-color: #eeffee;
margin-top: 5px;
margin-bottom: 5px;
margin-left: 5px;
margin-right: 5px;
}
div#canvas-frame2{
border: none;
cursor: pointer;
width: 300px;
height: 300px;
background-color: #eeeeff;
margin-top: 5px;
margin-bottom: 5px;
margin-left: 5px;
margin-right: 5px;
}
div#canvas-frame3{
border: none;
cursor: pointer;
width: 300px;
height: 300px;
background-color: #f5deb3;
margin-top: 5px;
margin-bottom: 5px;
margin-left: 5px;
margin-right: 5px;
}
div#mymessage {
margin-top: 5px;
background-color: #ffffff;
margin-bottom: 5px;
}
div#mymessage2 {
margin-top: 5px;
width: 190px;
background-color: #ffffff;
margin-bottom: 5px;
}
div#slider {
margin-top: 5px;
margin-bottom: 5px;
margin-left: 0px;
margin-right: 5px;
width: 190px;
padding: 5px 5px 5px 5px;
border-color: #cccccc;
border-width: 1px;
border-style: solid;
background-color: #ffffff;
}
body {
font-family: 'Righteous', cursive;
}
</style>
<script>
var t, tb4= -1.0, istep = 0, ijump = 6;
var fsample=11025.0, nch=1;
var dt = 1.0/fsample;
var dsize = 700;
var nbin = 100;
var index;
var start_time, elapsed_time, elapsed_timeb4 = -1.0;
function loop2() {
var d1 = []; var d2 = []; var d3 = []; var d4 = [];
var i;
if(t != tb4) {
index = Math.floor( t * (fsample*nch) );
tb4 = t;
for(i=0;i<nbin;i++) {
bin[i] = 0;
}
}
if( istep++ % ijump == 0) {
elapsed_time = new Date().getTime();
document.getElementById("mymessage2").innerHTML
= "Frame per second = "
+ (1000.0 / (elapsed_time - elapsed_timeb4)).toFixed(1);
elapsed_timeb4 = elapsed_time;
for(i=0;i<dsize;i++) {
d1.push([i, arr[index ]/32768.0]);
d2.push([i, arr[index+1]/32768.0]);
d3.push([ arr[index ]/32768.0, arr[index+1]/32768.0]);
ibin = Math.floor( (nbin/2)*(arr[index]/32768.0+1.0) );
bin[ibin]++;
index+=nch;
}
for(i=0;i<nbin;i++) {
d4.push([-1.0+2.0*(i/nbin), bin[i]]);
}
basic_legend (document.getElementById("canvas-frame" ), d1, d2);
basic_legend2(document.getElementById("canvas-frame2"), d3);
basic_legend3(document.getElementById("canvas-frame3"), d4);
}
window.requestAnimationFrame(loop2);
}
function basic_legend(container, d1, d2) {
var data, graph, i;
data = [
{ data : d1, label :'Ch Left' },
{ data : d2, label :'Ch Right' }
];
function labelFn (label) {
return label;
}
graph = Flotr.draw(container, data, {
legend : {
position : 'nw',
labelFormatter : labelFn,
backgroundColor : '#ffffcc'
},
yaxis : {
max : 1.1,
min : -1.1
},
HtmlText : false
});
}
function basic_legend2(container, d3) {
var data, graph, i;
data = [
{ data : d3, label :'Lissajous' }
];
function labelFn (label) {
return label;
}
graph = Flotr.draw(container, data, {
legend : {
position : 'nw',
labelFormatter : labelFn,
backgroundColor : '#ffffcc'
},
colors : [ '#ffa500' ],
xaxis : {
max : 1.1,
min : -1.1
},
yaxis : {
max : 1.1,
min : -1.1
},
HtmlText : false
});
}
function basic_legend3(container, d4) {
var data, graph, i;
data = [
{ data : d4, label :'Histogram' }
];
function labelFn (label) {
return label;
}
graph = Flotr.draw(container, data, {
legend : {
position : 'nw',
labelFormatter : labelFn,
backgroundColor : '#ffffcc'
},
colors : [ '#8a2be2' ],
xaxis : {
max : 1.1,
min : -1.1
},
yaxis : {
max : 420,
min : -20
},
HtmlText : false
});
}
</script>
<script>
function audioPlay() {
var files = document.getElementById('files').files;
var file = files[0];
if (!files.length) {
alert('Please select a wave file!');
return;
}
if (file.type.match(/audio.*/)) {
var reader2 = new FileReader();
reader2.onload = function(d) {
e = document.createElement("audio");
e.src = d.target.result;
e.setAttribute("type", file.type);
e.setAttribute("controls", "controls");
e.setAttribute("autoplay", "true");
document.getElementById("container").appendChild(e);
e.addEventListener("timeupdate", function() {
t=e.currentTime;
}, false);
};
reader2.readAsDataURL(file);
}
}
function readBlob() {
var files = document.getElementById('files').files;
if (!files.length) {
alert('Please select a wave file!');
return;
}
var file = files[0];
var header_length = 44; // wave file
var start = 0; // do not skip header
var stop = file.size - 1; // read until EOF
var nbyte = file.size - header_length;
var ndata = nbyte / 2; // 2 byte per data for 16-bit PCM
var reader = new FileReader();
reader.onloadend = function(evt) {
if (evt.target.readyState == FileReader.DONE) { // DONE == 2
var buffer = reader.result;
arr = new Int16Array(buffer);
arr2 = new Uint8Array(buffer);
arrmax = 0;
arrmin = 0;
arrmax_pos = 0;
arrmin_pos = 0;
arr_pos = 0;
start_time = new Date().getTime();
bin = new Array();
var i;
for(i=0;i<nbin;i++) {
bin[i] = 0;
}
var istart = header_length/2; // skip header
for(i=istart;i<ndata;i++) {
if(arr[i] > arrmax) {
arrmax = arr[i];
arrmax_pos = i;
}
if(arr[i] < arrmin) {
arrmin = arr[i];
arrmin_pos = i;
}
}
if( arrmax > Math.abs(arrmin) ) {
arr_pos = arrmax_pos;
} else {
arr_pos = arrmin_pos;
}
index = 0;
t = index / (fsample*nch);
if(arr2[8]==0x57 && arr2[9]==0x41 && arr2[10]==0x56 && arr2[11]==0x45) {
fsample = arr2[24]+256*arr2[25]+256*256*arr2[26]+256*256*256*arr2[27];
nch = arr2[22]+256*arr2[23];
document.getElementById('mymessage').innerHTML = "WAVE file: fsample = " + fsample + ", nch = " + nch;
} else {
document.getElementById('mymessage').innerHTML = "not a WAVE file. ";
}
loop2();
}
};
var blob = file.slice(start, stop + 1);
reader.readAsArrayBuffer(blob);
}
function upRate() {
ijump--;
if(ijump < 1) ijump = 1;
}
function downRate() {
ijump++;
if(ijump > 10) ijump = 10;
}
</script>
</head>
<body>
<div id="canvas-frame" style="float:left"></div>
<div id="canvas-frame2" style="float:left"></div>
<div id="canvas-frame3" style="float:left"></div>
<div style="clear:both"><h1>Wavefile Read</h1></dvi>
<input type="file" id="files" style="width:400px;" multiple/>
<div id="mymessage"></div>
<div id="slider">FPS slider
<input id="range01" type="range" min="1" max="10" step="1" onchange="showValue()"/>
<div id="mymessage2"></div>
</div>
<div id="container"></div>
<script type="text/javascript">
function showValue () {
ijump = document.getElementById("range01").value;
}
</script>
<script>
document.getElementById("files").addEventListener("change", readBlob, false);
document.getElementById("files").addEventListener("change", audioPlay, false);
</script>
</body>
</html>
