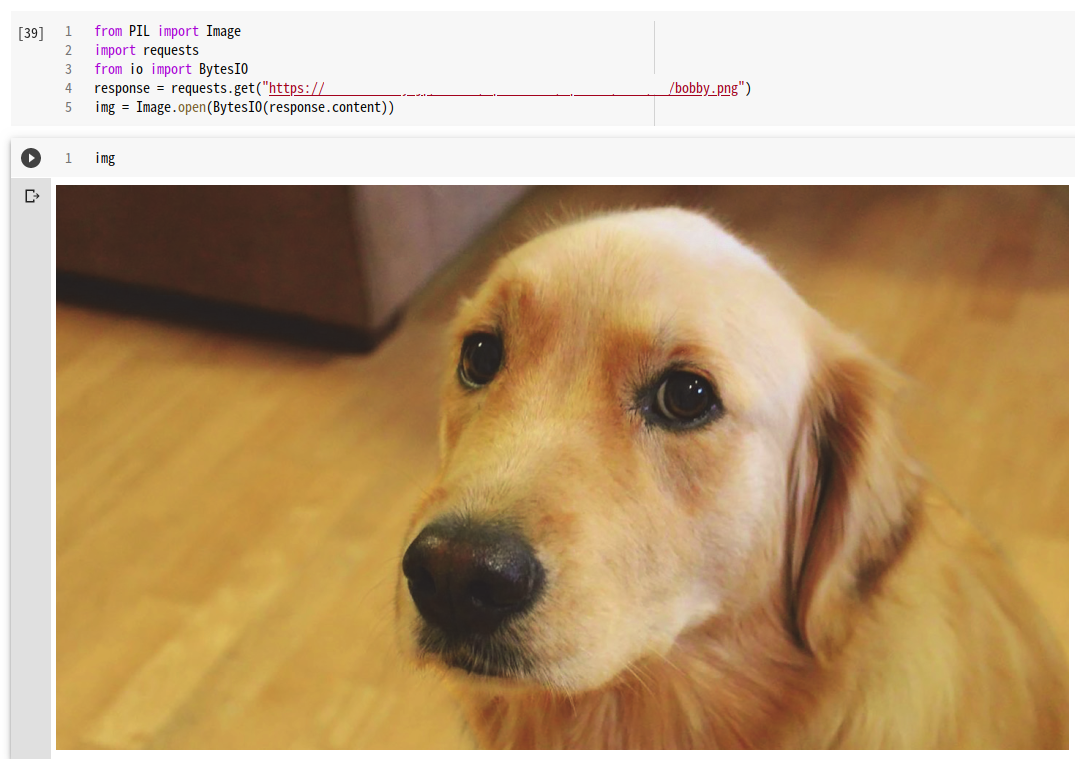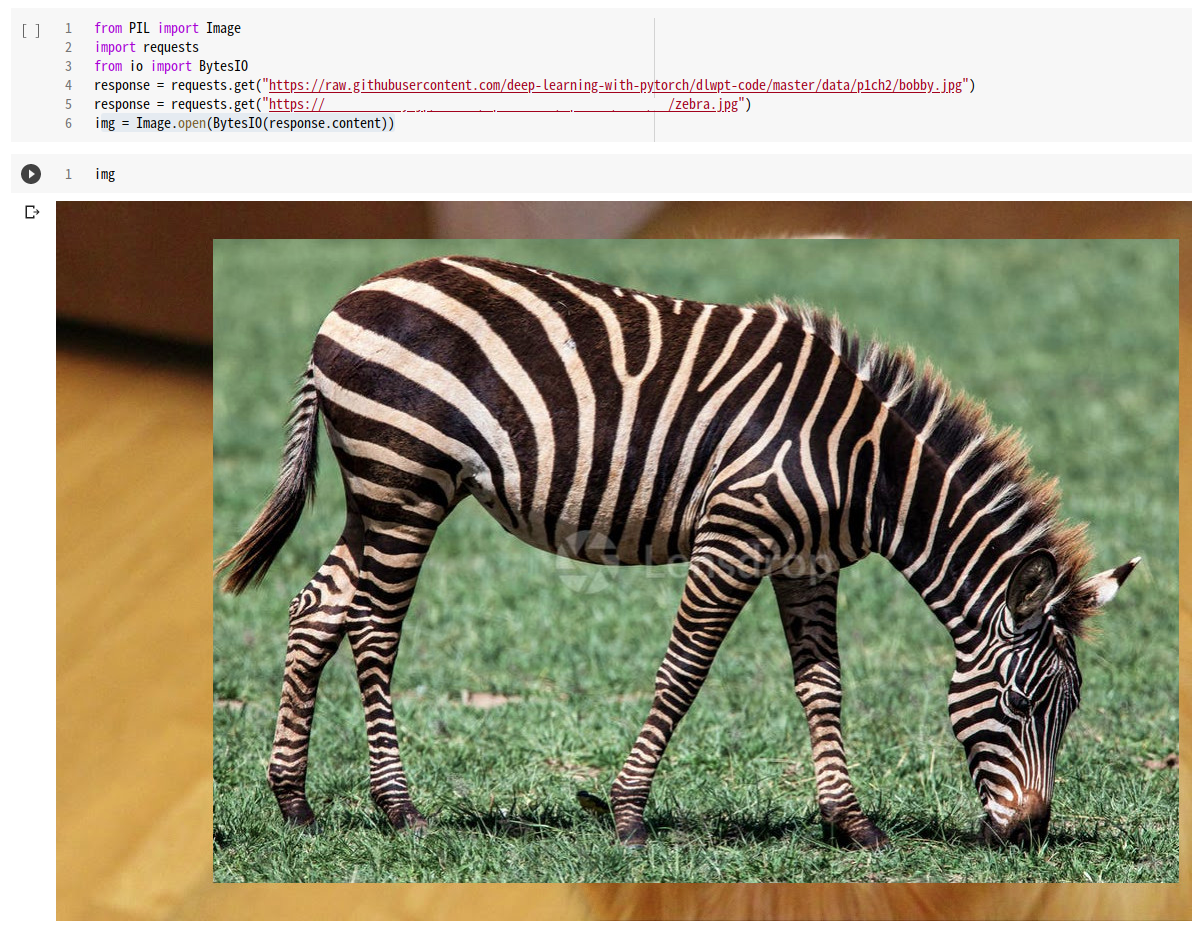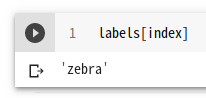
$ docker login Login Succeeded $ docker push spinorlab/mytest2:latest The push refers to repository [docker.io/spinorlab/mytest2] 5029f7ee982d: Pushed 9ad1613bbd61: Mounted from tensorflow/tensorflow e1d989f7dcf7: Mounted from tensorflow/tensorflow 121b52b5f422: Mounted from tensorflow/tensorflow 15438b600e27: Mounted from tensorflow/tensorflow a277414bc98e: Mounted from tensorflow/tensorflow 2ea460eb43f3: Mounted from tensorflow/tensorflow 1206fb09b65f: Mounted from tensorflow/tensorflow 06211822af79: Mounted from tensorflow/tensorflow d0dc22652f23: Mounted from tensorflow/tensorflow 808186df4412: Mounted from tensorflow/tensorflow c67444e4a455: Mounted from tensorflow/tensorflow e46b1edd096d: Mounted from tensorflow/tensorflow a54221677577: Mounted from tensorflow/tensorflow 3635245ebf45: Mounted from tensorflow/tensorflow fc1de999a67f: Mounted from tensorflow/tensorflow 459ab4b91080: Mounted from tensorflow/tensorflow 15d8713e46ff: Mounted from tensorflow/tensorflow cbad238d3511: Mounted from tensorflow/tensorflow 8e1d800aec8e: Mounted from tensorflow/tensorflow 8001ac9daff0: Mounted from tensorflow/tensorflow 2cdb2c6a3a9c: Mounted from tensorflow/tensorflow a7bb72101540: Mounted from tensorflow/tensorflow 04ec0c2fd468: Mounted from tensorflow/tensorflow 8682f9a74649: Mounted from tensorflow/tensorflow d3a6da143c91: Mounted from tensorflow/tensorflow 83f4287e1f04: Mounted from tensorflow/tensorflow 7ef368776582: Mounted from tensorflow/tensorflow latest: digest: sha256:455683d0938c821775548a728ada4f332b8a8a24ee5f4846e59dd6df1cc8930c size: 6177
IMAGE ID CREATED SIZE
tensorflow/tensorflow latest-jupyter 2d87e2e84687 10 days ago 1.69GB
tensorflow/tensorflow latest 539d0e818045 10 days ago 1.54GB
$ docker run -it -p 8888:8888 spinorlab/mytest2
Unable to find image 'spinorlab/mytest2:latest' locally
latest: Pulling from spinorlab/mytest2
7595c8c21622: Already exists
d13af8ca898f: Already exists
70799171ddba: Already exists
b6c12202c5ef: Already exists
e85a7daf82bf: Already exists
83af0ea793b7: Already exists
34fa049596e7: Already exists
dc1cc2fe1e0c: Already exists
1a5aee8cf91a: Already exists
31d48fae49f8: Already exists
3a1b491b29e7: Already exists
07e490e2f08a: Already exists
6eaf16807188: Already exists
a9f79dabae8c: Already exists
c826fed7e446: Already exists
9fd0905294ac: Already exists
12bb1b3645cf: Already exists
37f7fe348b69: Already exists
b8eafc2f4569: Already exists
416fc2f51eba: Already exists
30d0c35e0b10: Already exists
94fbeeb8d0c4: Already exists
5f2b7dc63f6f: Already exists
23ab0f6c8495: Already exists
e987a9b2b4b3: Already exists
dff8619d554c: Already exists
206cc04ed7f4: Already exists
332e2a286694: Pull complete
Digest: sha256:455683d0938c821775548a728ada4f332b8a8a24ee5f4846e59dd6df1cc8930c
Status: Downloaded newer image for spinorlab/mytest2:latest
[I 00:25:45.062 NotebookApp] Writing notebook server cookie secret to /root/.local/share/jupyter/runtime/notebook_cookie_secret
jupyter_http_over_ws extension initialized. Listening on /http_over_websocket
[I 00:25:45.273 NotebookApp] Serving notebooks from local directory: /tf
[I 00:25:45.273 NotebookApp] The Jupyter Notebook is running at:
[I 00:25:45.273 NotebookApp] http://d8508a271901:8888/?token=f326bec7f79b9cc51a90929026b2d2bd02beec1fc6e1d993
[I 00:25:45.273 NotebookApp] or http://127.0.0.1:8888/?token=f326bec7f79b9cc51a90929026b2d2bd02beec1fc6e1d993
[I 00:25:45.273 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
[C 00:25:45.277 NotebookApp]
To access the notebook, open this file in a browser:
file:///root/.local/share/jupyter/runtime/nbserver-1-open.html
Or copy and paste one of these URLs:
http://d8508a271901:8888/?token=f326bec7f79b9cc51a90929026b2d2bd02beec1fc6e1d993
or http://127.0.0.1:8888/?token=f326bec7f79b9cc51a90929026b2d2bd02beec1fc6e1d993