
また別のタイプのトレーニングシーケンスは、こんな感じです。
a, 10111000
a, 10111000
aa, 1011100010111000
(many lines deleted)
zythia, 111011101010001110101110111000111000101010100010100010111000
zythum, 111011101010001110101110111000111000101010100010101110001110111000
zyzomys, 11101110101000111010111011100011101110101000111011101110001110111000111010111011100010101000
zyzzogeton, 11101110101000111010111011100011101110101000111011101010001110111011100011101110100010001110001110111011100011101000
“000”は、文字間のスペースを表しています。
11101011101000111011101110001110101110100010111000 coca coca 1110101110100010111000101010001000 case case 111010111010001011100010111010001110101000 card card 101010001011101110001010001110111000 swim swim 11101110100010111000101011101000101011101000 gaff gaff 11101011101000101110001010111010001010101000 cafh caln 1010101000101000111010001110101000 hind hind
さらに、別のタイプです。
a, 1 111
aa, 1 111 1 111
aal, 1 111 1 111 1 111 1 1
aalii, 1 111 1 111 1 111 1 1 1 1 1 1
(many lines deleted)
zythia, 111 111 1 1 111 1 111 111 111 1 1 1 1 1 1 1 111
zythum, 111 111 1 1 111 1 111 111 111 1 1 1 1 1 1 111 111 111
zyzomys, 111 111 1 1 111 1 111 111 111 111 1 1 111 111 111 111 111 111 1 111 111 1 1 1
zyzzogeton, 111 111 1 1 111 1 111 111 111 111 1 1 111 111 1 1 111 111 111 111 111 1 1 111 111 111 111 111 1
この方が、あなたには読みやすいですか。
1 1 111 1 1 1 111 1 1 111 111 111 fido fido 1 111 111 1 1 1 111 1 1 adai adai 1 111 1 1 111 111 1 1 1 111 rada rada 1 111 1 111 1 1 1 111 111 alem alem 1 111 111 1 1 1 111 1 111 1 1 pice pice 1 111 111 1 111 111 1 111 1 111 111 eggy egcy 1 111 111 1 1 111 1 111 1 1 1 pale pale
以下の例では、4文字未満の単語も含まれています。
1 111 1 1 ai ai 111 1 111 111 111 111 111 1 1 111 you you 111 1 1 111 111 1 1 111 tutu tutu 1 1 111 1 111 111 111 111 1 1 111 111 1 111 111 foxy foxy 1 1 1 1 111 111 111 111 1 1 hoti hott 111 1 111 1 1 1 111 111 1 1 111 cepa cepa 111 111 1 1 1 111 111 gut gut
from keras.models import Sequential
from keras import layers
import numpy as np
import matplotlib.pyplot as plt
class CharTable(object):
def __init__(self, chars):
self.chars = sorted(set(chars))
self.char_indices = dict((c, i) for i, c in enumerate(self.chars))
self.indices_char = dict((i, c) for i, c in enumerate(self.chars))
def encode(self, token, num_rows):
x = np.zeros((num_rows, len(self.chars)))
for i, c in enumerate(token):
x[i, self.char_indices] = 1
return x
def decode(self, x, calc_argmax=True):
if calc_argmax:
x = [x.argmax(axis=-1)]
return ''.join(self.indices_char[int(v)] for v in x)
def main():
word_len = 4
max_len_x = 15 * word_len + 2*(word_len - 1)
max_len_y = word_len
input_list = []
output_list = []
fin = 'words_morse1only.txt'
with open(fin, 'r') as file:
for line in file.read().splitlines():
mylist = line.split(", ")
[word, morse] = mylist
morse = morse + ' ' * (max_len_x - len(morse))
if len(word) <= word_len:
word = word + ' ' * (word_len - len(word))
input_list.append(morse)
output_list.append(word)
print("input_list = ", input_list[:5])
print("output_list = ", output_list[:5])
# chars_in = '10 '
chars_in = '1 '
chars_out = 'abcdefghijklmnopqrstuvwxyz '
ctable_in = CharTable(chars_in)
ctable_out = CharTable(chars_out)
x = np.zeros((len(input_list), max_len_x, len(chars_in)))
y = np.zeros((len(output_list), max_len_y, len(chars_out)))
for i, token in enumerate(input_list):
x[i] = ctable_in.encode(token, max_len_x)
for i, token in enumerate(output_list):
y[i] = ctable_out.encode(token, max_len_y)
indices = np.arange(len(y))
np.random.shuffle(indices)
x = x[indices]
y = y[indices]
m = len(x) - 100
(x_train, x_val) = x[:m], x[m:]
(y_train, y_val) = y[:m], y[m:]
hidden_size = 64
batch_size = 128
nlayers = 1
epochs = 600
model = Sequential()
model.add(layers.LSTM(hidden_size, input_shape=(max_len_x, len(chars_in))))
model.add(layers.RepeatVector(word_len))
for _ in range(nlayers):
model.add(layers.LSTM(hidden_size, return_sequences=True))
model.add(layers.TimeDistributed(layers.Dense(len(chars_out), activation='softmax')))
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
model.summary()
hist = model.fit(x_train, y_train, batch_size=batch_size,
epochs=epochs, verbose=2, validation_data=(x_val, y_val))
predict = model.predict_classes(x_val)
for i in range(len(x_val)):
print("".join([ctable_in.decode(code) for code in x_val[i]]),
"".join([ctable_out.decode(code) for code in y_val[i]]), end=" ")
for j in range(word_len):
print(ctable_out.indices_char[predict[i][j]], end="")
print()
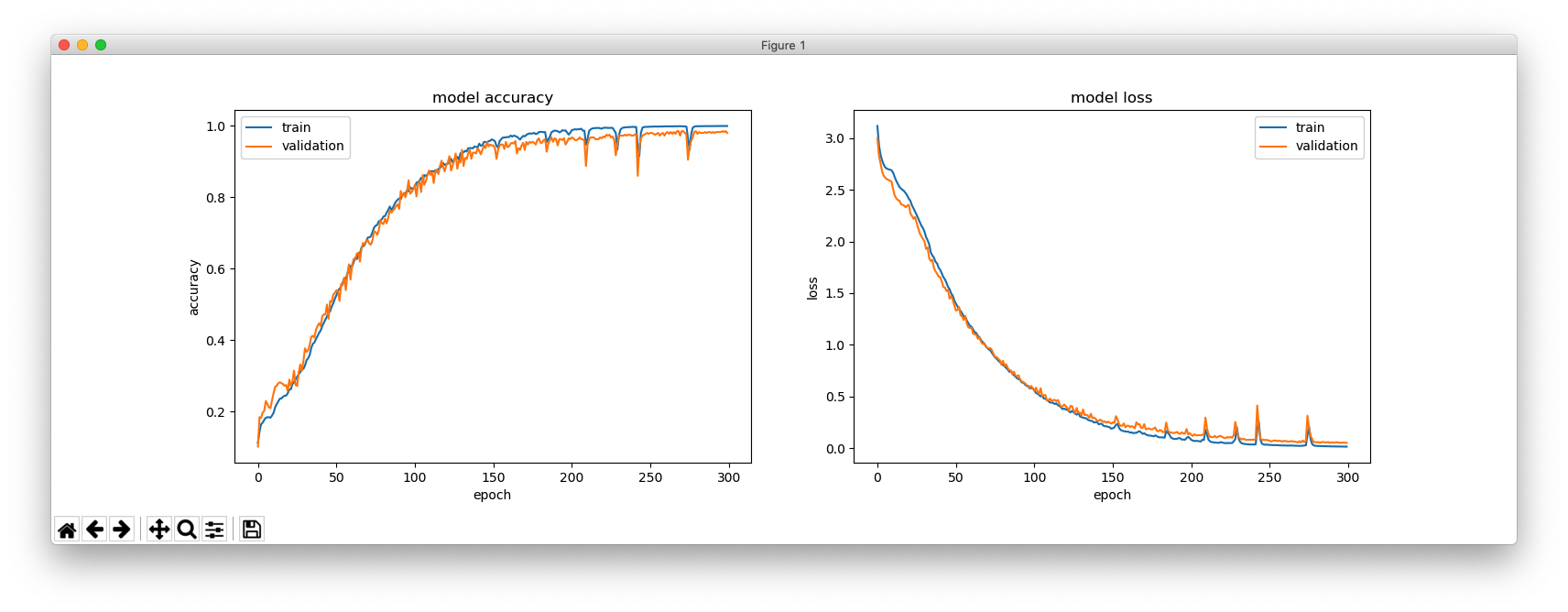
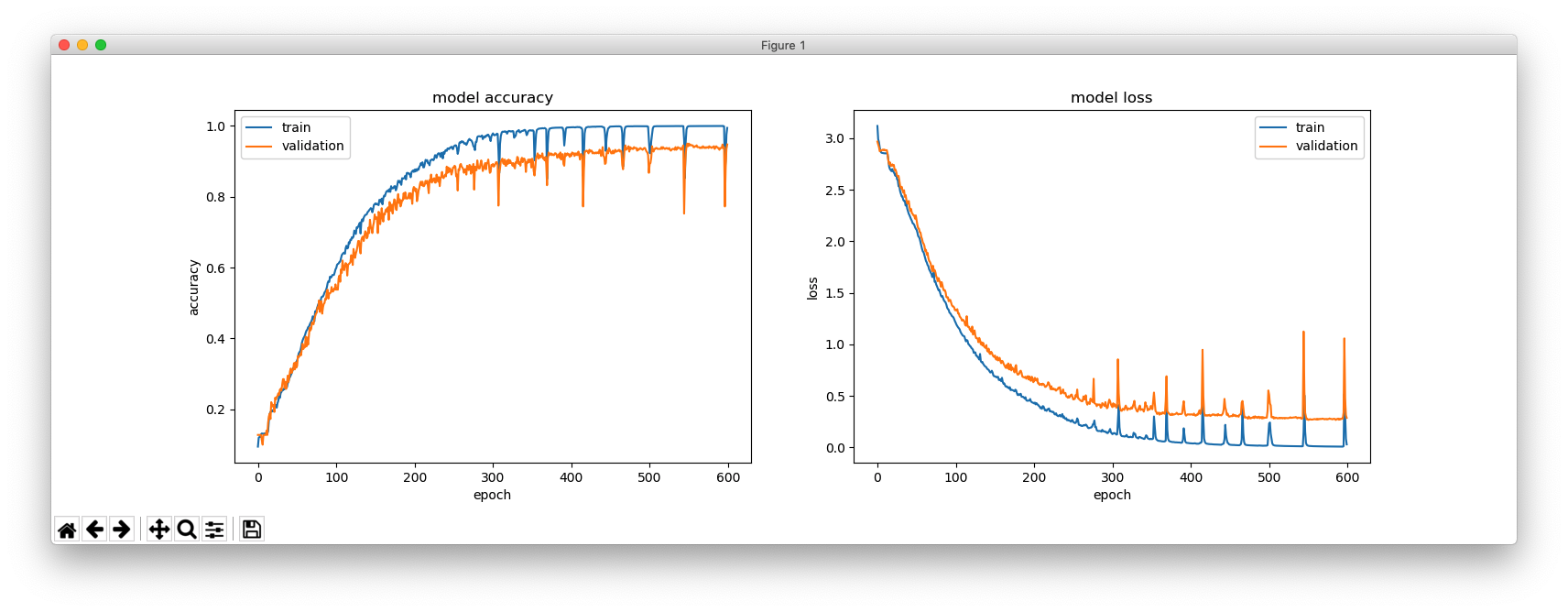
plt.figure(figsize=(16, 5))
plt.subplot(121)
plt.plot(hist.history['acc'])
plt.plot(hist.history['val_acc'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'validation'], loc='upper left')
plt.subplot(122)
plt.plot(hist.history['loss'])
plt.plot(hist.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'validation'], loc='upper right')
plt.show()
main()