
ALL THESE WORLDS ARE YOURS, EXCEPT EUROPA.
ATTEMPT NO LANDING THERE.
USE THEM TOGETHER.
USE THEM IN PEACE.

Ham Radio Blog
ALL THESE WORLDS ARE YOURS, EXCEPT EUROPA.
ATTEMPT NO LANDING THERE.
USE THEM TOGETHER.
USE THEM IN PEACE.
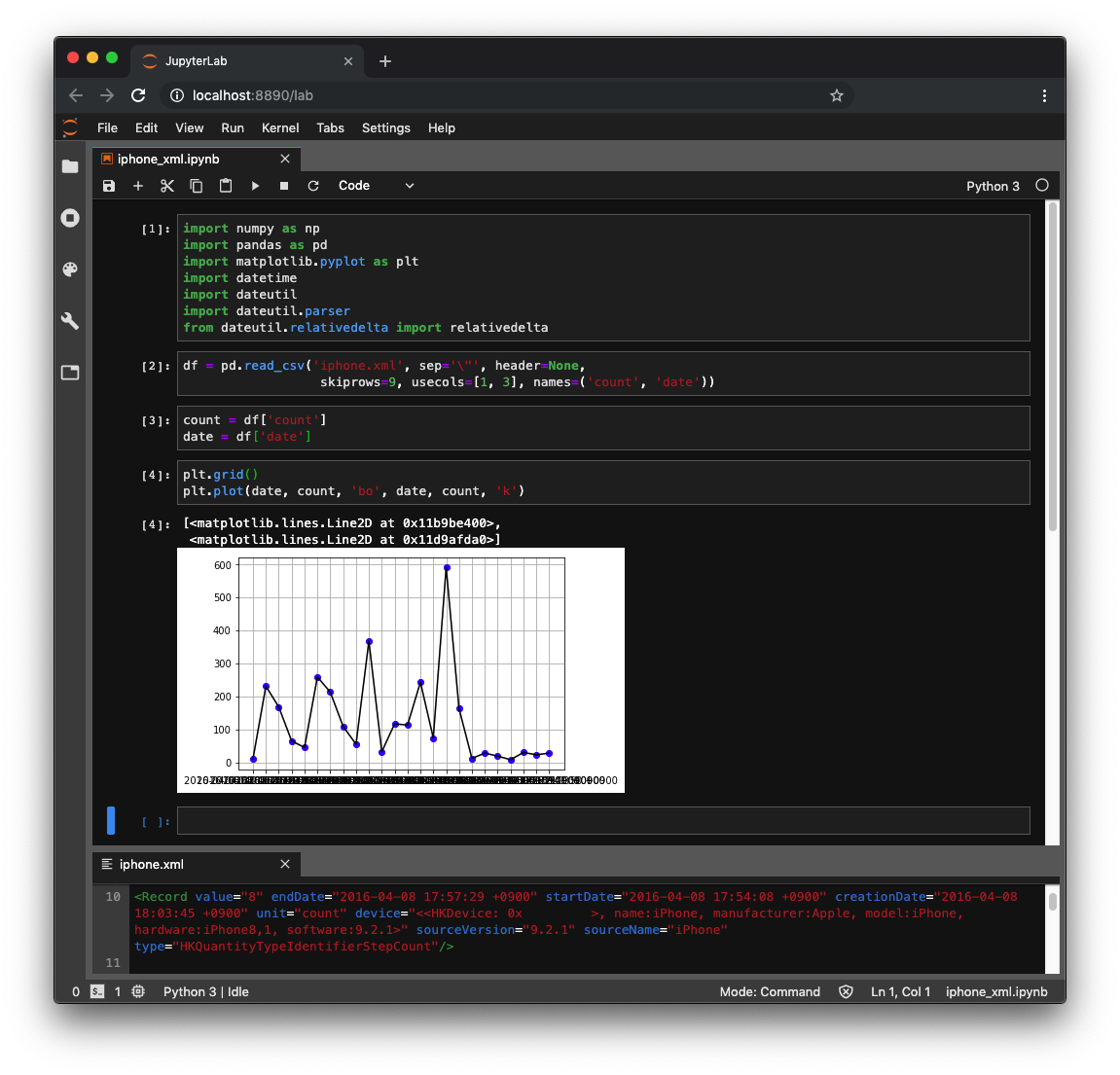
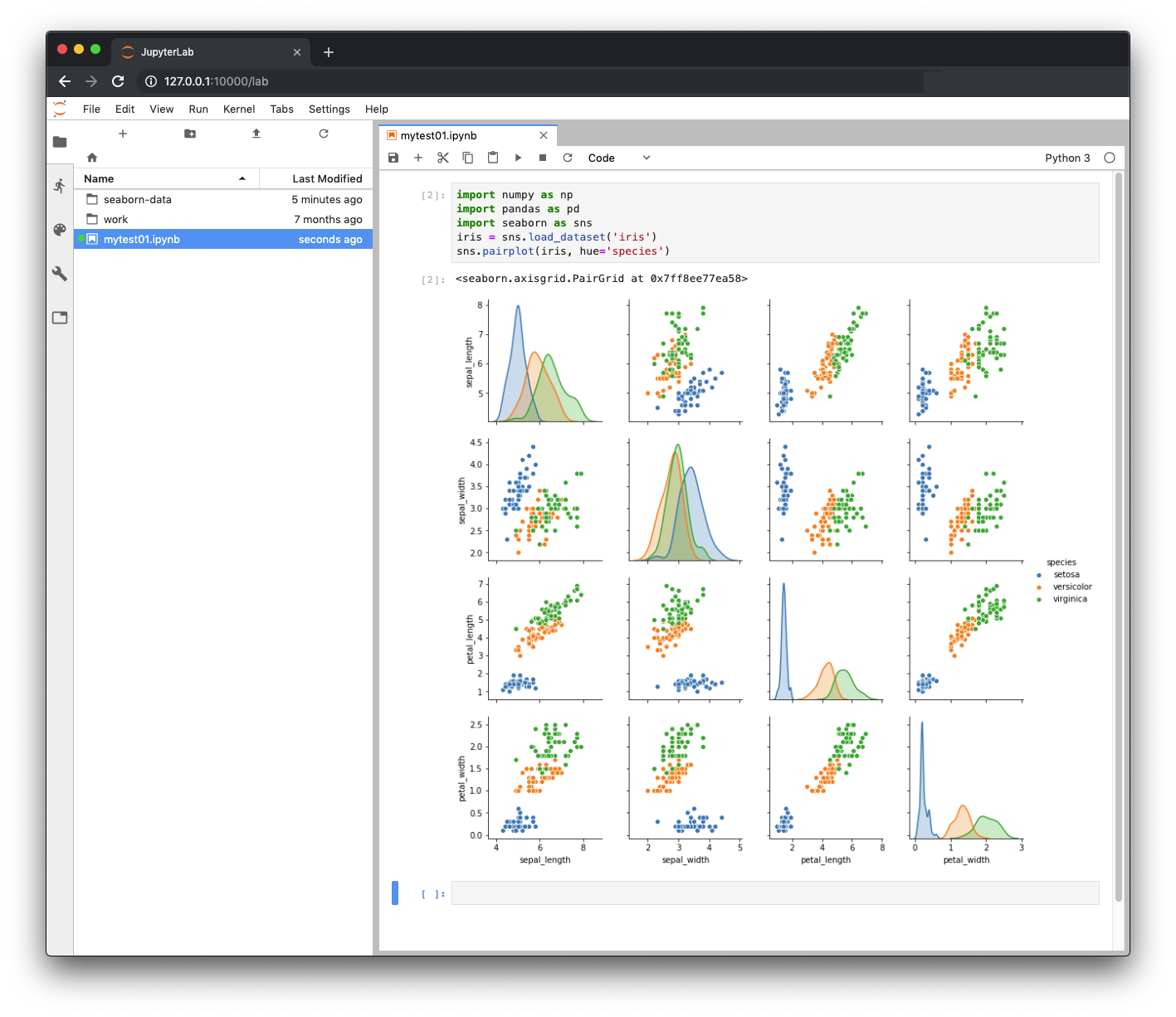
JupyterLab is a web-based interactive development environment for Jupyter notebooks, code, and data.
私自身は、PyCharmの方が好きですが、状況によっては JupyterLab がベストということもあるでしょう。
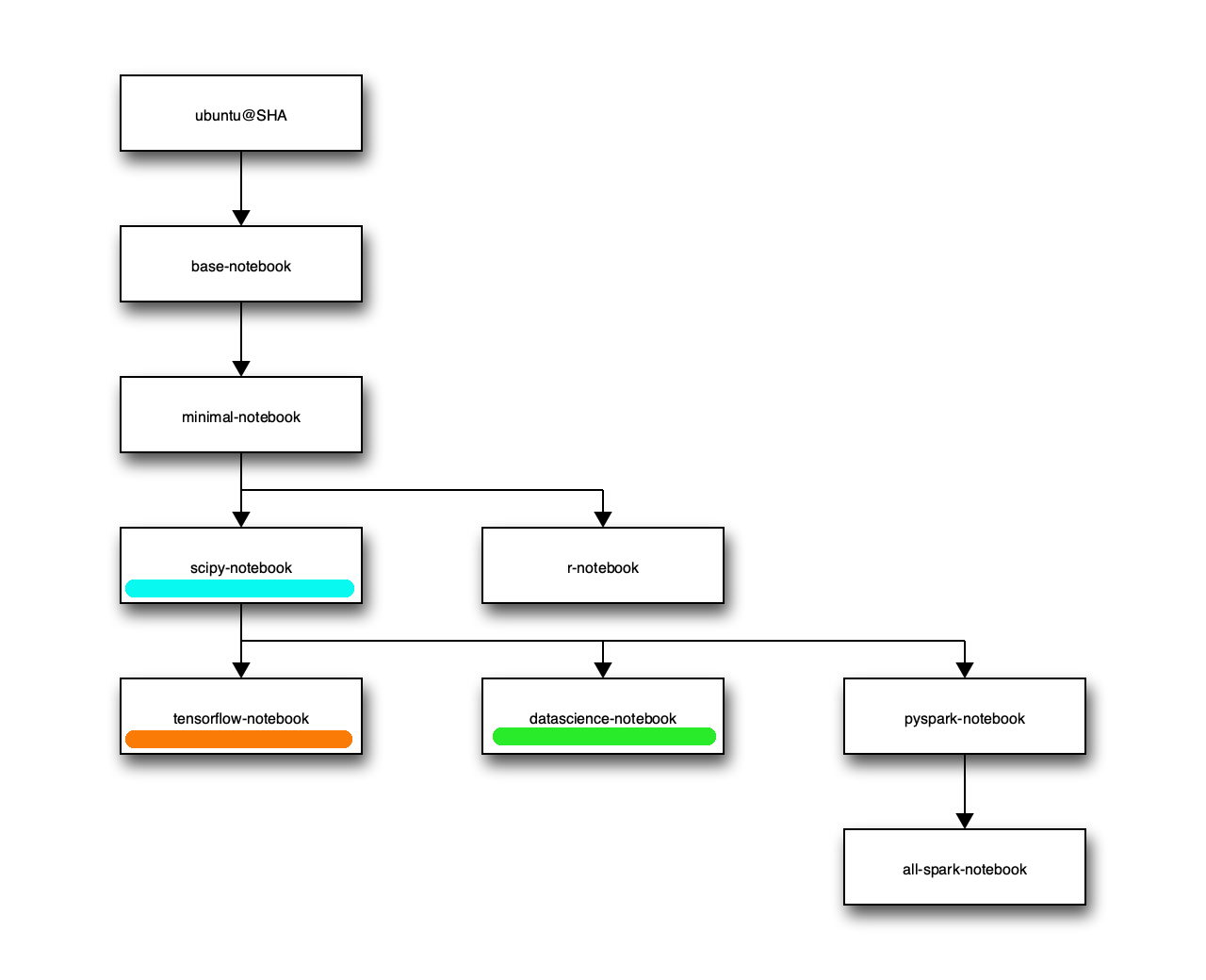
いろんなタイプのdockerイメージがあります。
$ docker run --rm -p 10000:8888 -e JUPYTER_ENABLE_LAB=yes -v "$PWD":/home/jovyan/work jupyter/scipy-notebook:17aba6048f44
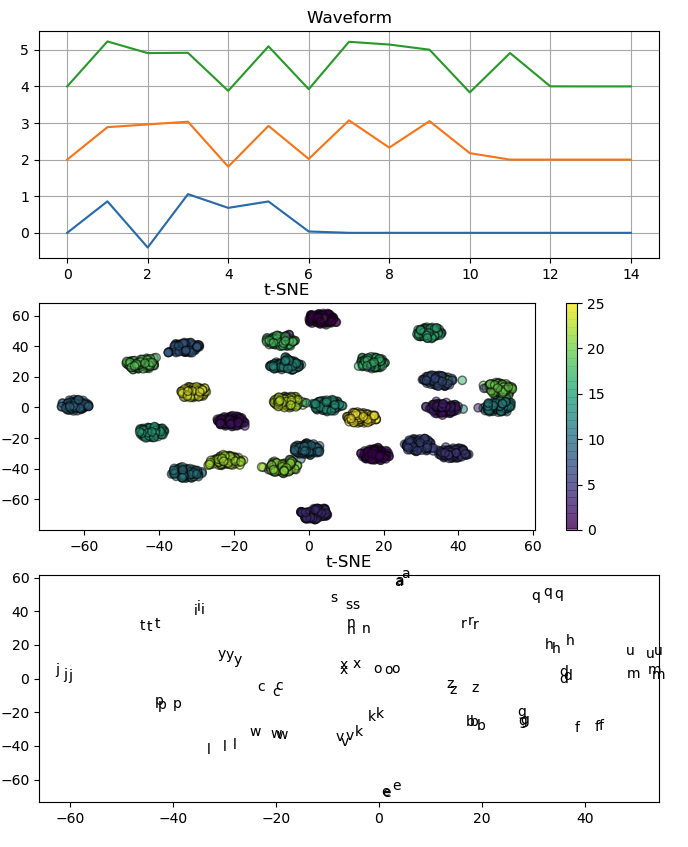
t-distributed Stochastic Neighbor Embedding (t-SNE)は、高次元のデータを可視化するためのツールです。
モールスコードでaからzを表している波形を、t-SNEを用いて2次元で可視化しています。
各信号は電気的に生成された後、ガウス雑音が加えられています。
import matplotlib.pyplot as plt
import numpy as np
from sklearn.manifold import TSNE
alphabet = list("abcdefghijklmnopqrstuvwxyz")
values = ['101110', '1110101010', '111010111010', '11101010', '10',
'1010111010', '1110111010', '10101010', '1010', '10111011101110',
'1110101110', '1011101010', '11101110', '111010', '111011101110',
'101110111010', '11101110101110', '10111010', '101010', '1110',
'10101110', '1010101110', '1011101110', '111010101110', '11101011101110',
'111011101010']
morse_dict = dict(zip(alphabet, values))
nrepeat = 100
n = len(values)
word_len = 15
X = np.zeros((n * nrepeat, word_len))
Y = np.zeros(n * nrepeat, dtype=np.int)
for rep in range(nrepeat):
for i, letter in enumerate(alphabet):
for j, char in enumerate(morse_dict[letter]):
X[i+rep * n][j+1] = (ord(char) - ord('0')) + np.random.normal(0.0, 0.2)
Y[i+rep * n] = i
X_reduced = TSNE(n_components=2, random_state=0).fit_transform(X)
plt.figure(figsize=(8, 12))
plt.subplot(3, 1, 1)
x = np.arange(word_len)
for i in range(3):
y = X[i, :] + 2.0 * i
plt.plot(x, y)
plt.grid()
plt.title('Waveform')
plt.subplot(3, 1, 2)
plt.scatter(X_reduced[:, 0], X_reduced[:, 1],
c=Y, edgecolors='black', alpha=0.5)
plt.colorbar()
plt.title('t-SNE')
plt.subplot(3, 1, 3)
for rep in range(min(3, nrepeat)):
for i, letter in enumerate(alphabet):
s = chr(Y[i] + ord('a'))
plt.text(X_reduced[i+rep*n, 0], X_reduced[i+rep*n, 1], s)
plt.xlim([min(X_reduced[:, 0]), max(X_reduced[:, 0])])
plt.ylim([min(X_reduced[:, 1]), max(X_reduced[:, 1])])
plt.title('t-SNE')
plt.show()
- Input sentence: -.-. --.- Decoded sentence: cy - Input sentence: --.- .-. -- Decoded sentence: qrm - Input sentence: --.- .-. --.. Decoded sentence: zrz - Input sentence: --.- ... -... Decoded sentence: qub - Input sentence: -.-- .- -... -... .-.. . Decoded sentence: yabble - Input sentence: -... .-. .- -. -.. Decoded sentence: brand - Input sentence: .-. . -.. --- .-- .- Decoded sentence: redowa - Input sentence: -.-. .- -- .. --- -. Decoded sentence: camion - Input sentence: .-. . -. -.. Decoded sentence: rend - Input sentence: -... .- .- .-. Decoded sentence: baar
上の単語は、全てトレーニング系列には含まれていないことに注意して下さい。
明らかに、私たちは私たちの辞書にプロサインとかQ符号を付け加えて拡張することが必要なようです。
from keras.models import Model
from keras.layers import Input, LSTM, Dense
import numpy as np
import random
import matplotlib.pyplot as plt
batch_size = 64
epochs = 100
latent_dim = 256
num_samples = 20000
data_path = '../keras015/words_morse.txt'
max_word_length = 6
lines = []
input_texts = []
target_texts = []
input_characters = set()
target_characters = set()
with open(data_path, 'r', encoding='utf-8') as f:
for line in f:
english_text, morse_text = line.split(', ')
if len(english_text) <= max_word_length:
lines.append(line.rstrip('\n'))
print("max_word_length = ", max_word_length)
print("no. of available words =", len(lines))
num_samples = min(num_samples, len(lines))
print("no. of words sampled = ", num_samples)
lines_sampled = random.sample(lines, k=num_samples)
lines_sampled[0] = 'cq, -.-. --.-'
lines_sampled[1] = 'qrm, --.- .-. --'
lines_sampled[2] = 'qrz, --.- .-. --..'
lines_sampled[3] = 'qsb, --.- ... -...'
print(lines_sampled[:10])
for line in lines_sampled:
target_text, input_text = line.split(', ')
target_text = '\t' + target_text + '\n'
input_texts.append(input_text)
target_texts.append(target_text)
for char in input_text:
if char not in input_characters:
input_characters.add(char)
for char in target_text:
if char not in target_characters:
target_characters.add(char)
input_characters = sorted(list(input_characters))
target_characters = sorted(list(target_characters))
num_encoder_tokens = len(input_characters)
num_decoder_tokens = len(target_characters)
max_encoder_seq_length = max([len(txt) for txt in input_texts])
max_decoder_seq_length = max([len(txt) for txt in target_texts])
print('Number of samples:', len(input_texts))
print('Number of unique input tokens:', num_encoder_tokens)
print('Number of unique output tokens:', num_decoder_tokens)
print('Max sequence length for inputs:', max_encoder_seq_length)
print('Max sequence length for outputs:', max_decoder_seq_length)
input_token_index = dict(
[(char, i) for i, char in enumerate(input_characters)])
target_token_index = dict(
[(char, i) for i, char in enumerate(target_characters)])
encoder_input_data = np.zeros(
(len(input_texts), max_encoder_seq_length, num_encoder_tokens),
dtype='float32')
decoder_input_data = np.zeros(
(len(input_texts), max_decoder_seq_length, num_decoder_tokens),
dtype='float32')
decoder_target_data = np.zeros(
(len(input_texts), max_decoder_seq_length, num_decoder_tokens),
dtype='float32')
for i, (input_text, target_text) in enumerate(zip(input_texts, target_texts)):
for t, char in enumerate(input_text):
encoder_input_data[i, t, input_token_index[char]] = 1.
for t, char in enumerate(target_text):
# decoder_target_data is ahead of decoder_input_data by one timestep
decoder_input_data[i, t, target_token_index[char]] = 1.
if t > 0:
# decoder_target_data will be ahead by one timestep
# and will not include the start character.
decoder_target_data[i, t - 1, target_token_index[char]] = 1.
m = len(encoder_input_data) // 4
(input_texts_val, input_texts_train) =\
input_texts[:m], input_texts[m:]
(encoder_input_data_val, encoder_input_data_train) =\
encoder_input_data[:m], encoder_input_data[m:]
(decoder_input_data_val, decoder_input_data_train) =\
decoder_input_data[:m], decoder_input_data[m:]
(decoder_target_data_val, decoder_target_data_train) =\
decoder_target_data[:m], decoder_target_data[m:]
print(len(encoder_input_data_val), len(encoder_input_data_train))
# Define an input sequence and process it.
encoder_inputs = Input(shape=(None, num_encoder_tokens))
encoder = LSTM(latent_dim, return_state=True)
encoder_outputs, state_h, state_c = encoder(encoder_inputs)
# We discard `encoder_outputs` and only keep the states.
encoder_states = [state_h, state_c]
# Set up the decoder, using `encoder_states` as initial state.
decoder_inputs = Input(shape=(None, num_decoder_tokens))
# We set up our decoder to return full output sequences,
# and to return internal states as well. We don't use the
# return states in the training model, but we will use them in inference.
decoder_lstm = LSTM(latent_dim, return_sequences=True, return_state=True)
decoder_outputs, _, _ = decoder_lstm(decoder_inputs,
initial_state=encoder_states)
decoder_dense = Dense(num_decoder_tokens, activation='softmax')
decoder_outputs = decoder_dense(decoder_outputs)
# Define the model that will turn
# `encoder_input_data` & `decoder_input_data` into `decoder_target_data`
model = Model([encoder_inputs, decoder_inputs], decoder_outputs)
# Run training
model.compile(optimizer='rmsprop', loss='categorical_crossentropy')
model.summary()
hist = model.fit([encoder_input_data_train, decoder_input_data_train], decoder_target_data_train,
validation_data=([encoder_input_data_val, decoder_input_data_val], decoder_target_data_val),
batch_size=batch_size, epochs=epochs,
verbose=2)
# Save model
model.save('s2s.h5')
# Next: inference mode (sampling).
# Here's the drill:
# 1) encode input and retrieve initial decoder state
# 2) run one step of decoder with this initial state
# and a "start of sequence" token as target.
# Output will be the next target token
# 3) Repeat with the current target token and current states
# Define sampling models
encoder_model = Model(encoder_inputs, encoder_states)
decoder_state_input_h = Input(shape=(latent_dim,))
decoder_state_input_c = Input(shape=(latent_dim,))
decoder_states_inputs = [decoder_state_input_h, decoder_state_input_c]
decoder_outputs, state_h, state_c = decoder_lstm(
decoder_inputs, initial_state=decoder_states_inputs)
decoder_states = [state_h, state_c]
decoder_outputs = decoder_dense(decoder_outputs)
decoder_model = Model(
[decoder_inputs] + decoder_states_inputs,
[decoder_outputs] + decoder_states)
# Reverse-lookup token index to decode sequences back to
# something readable.
reverse_input_char_index = dict(
(i, char) for char, i in input_token_index.items())
reverse_target_char_index = dict(
(i, char) for char, i in target_token_index.items())
def decode_sequence(input_seq):
# Encode the input as state vectors.
states_value = encoder_model.predict(input_seq)
# Generate empty target sequence of length 1.
target_seq = np.zeros((1, 1, num_decoder_tokens))
# Populate the first character of target sequence with the start character.
target_seq[0, 0, target_token_index['\t']] = 1.
# Sampling loop for a batch of sequences
# (to simplify, here we assume a batch of size 1).
stop_condition = False
decoded_sentence = ''
while not stop_condition:
output_tokens, h, c = decoder_model.predict(
[target_seq] + states_value)
# Sample a token
sampled_token_index = np.argmax(output_tokens[0, -1, :])
sampled_char = reverse_target_char_index[sampled_token_index]
decoded_sentence += sampled_char
# Exit condition: either hit max length
# or find stop character.
if (sampled_char == '\n' or
len(decoded_sentence) > max_decoder_seq_length):
stop_condition = True
# Update the target sequence (of length 1).
target_seq = np.zeros((1, 1, num_decoder_tokens))
target_seq[0, 0, sampled_token_index] = 1.
# Update states
states_value = [h, c]
return decoded_sentence
def main():
for seq_index in range(10):
# Take one sequence (part of the training set)
# for trying out decoding.
input_seq = encoder_input_data_val[seq_index: seq_index + 1]
decoded_sentence = decode_sequence(input_seq)
print('-')
print('Input sentence:', input_texts_val[seq_index])
print('Decoded sentence:', decoded_sentence)
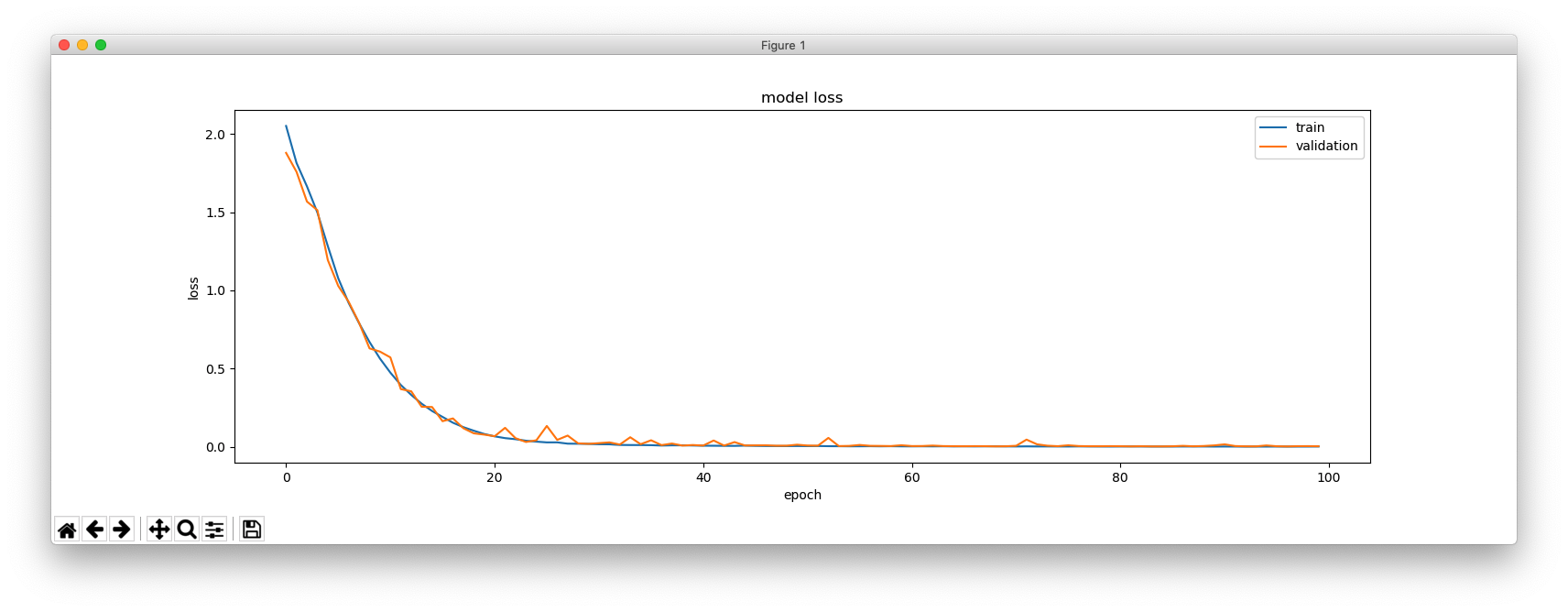
print(hist.history.keys())
plt.figure(figsize=(16, 5))
plt.plot(hist.history['loss'])
plt.plot(hist.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'validation'], loc='upper right')
plt.show()
main()
a, .-
aa, .- .-
aal, .- .- .-..
aalii, .- .- .-.. .. ..
(many lines deleted)
zythia, --.. -.-- - .... .. .-
zythum, --.. -.-- - .... ..- --
zyzomys, --.. -.-- --.. --- -- -.-- ...
zyzzogeton, --.. -.-- --.. --.. --- --. . - --- -.
同じトレーニング系列を用いて、入力とターゲットとを逆にしてみます。
# input_text, target_text = line.split(', ')
target_text, input_text = line.split(', ')
トレーニングをしばらく行うと、さて、CWが読めるようになりました!
- Input sentence: .- -- . -. -.. . Decoded sentence: amende - Input sentence: ... - --- -.-. .- .... Decoded sentence: stocah - Input sentence: --. .-. --- .--. . Decoded sentence: grope - Input sentence: -... --- --. .- -. Decoded sentence: bogan - Input sentence: .. -- -... . .-. Decoded sentence: imber - Input sentence: -... .- -.-. -.-. .- Decoded sentence: bacca - Input sentence: .. -. -.. ..- -.-. . Decoded sentence: induce - Input sentence: ..-. .- -. Decoded sentence: fan - Input sentence: -.. .. .-. -.. Decoded sentence: dird - Input sentence: .- .-.. .-.. .. . Decoded sentence: allie
悪く無いでしょう?
max_word_lenght = 6
no. of available words = 33887
no. of words sampled = 10000
['amende, .- -- . -. -.. .\n', 'stocah, ... - --- -.-. .- ....\n', 'grope, --. .-. --- .--. .\n']
Number of samples: 10000
Number of unique input tokens: 4
Number of unique output tokens: 28
Max sequence length for inputs: 29
Max sequence length for outputs: 8
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) (None, None, 4) 0
__________________________________________________________________________________________________
input_2 (InputLayer) (None, None, 28) 0
__________________________________________________________________________________________________
lstm_1 (LSTM) [(None, 256), (None, 267264 input_1[0][0]
__________________________________________________________________________________________________
lstm_2 (LSTM) [(None, None, 256), 291840 input_2[0][0]
lstm_1[0][1]
lstm_1[0][2]
__________________________________________________________________________________________________
dense_1 (Dense) (None, None, 28) 7196 lstm_2[0][0]
==================================================================================================
Total params: 566,300
Trainable params: 566,300
Non-trainable params: 0
__________________________________________________________________________________________________
Train on 8000 samples, validate on 2000 samples
Epoch 1/50
from keras.models import Model
from keras.layers import Input, LSTM, Dense
import numpy as np
import random
import matplotlib.pyplot as plt
batch_size = 64 # Batch size for training.
epochs = 50 # Number of epochs to train for.
latent_dim = 256 # Latent dimensionality of the encoding space.
num_samples = 10000 # Number of samples to train on.
data_path = '../keras015/words_morse.txt'
max_word_length = 6
# Vectorize the data.
lines = []
input_texts = []
target_texts = []
input_characters = set()
target_characters = set()
with open(data_path, 'r', encoding='utf-8') as f:
for line in f:
english_text, morse_text = line.split(', ')
if len(english_text) <= max_word_length:
lines.append(line)
print("max_word_lenght = ", max_word_length)
print("no. of available words =", len(lines))
num_samples = min(num_samples, len(lines))
print("no. of words sampled = ", num_samples)
lines_sampled = random.sample(lines, k=num_samples)
print(lines_sampled[:3])
for line in lines_sampled:
# input_text, target_text = line.split(', ')
target_text, input_text = line.split(', ')
target_text = '\t' + target_text + '\n'
input_texts.append(input_text)
target_texts.append(target_text)
for char in input_text:
if char not in input_characters:
input_characters.add(char)
for char in target_text:
if char not in target_characters:
target_characters.add(char)
input_characters = sorted(list(input_characters))
target_characters = sorted(list(target_characters))
num_encoder_tokens = len(input_characters)
num_decoder_tokens = len(target_characters)
max_encoder_seq_length = max([len(txt) for txt in input_texts])
max_decoder_seq_length = max([len(txt) for txt in target_texts])
print('Number of samples:', len(input_texts))
print('Number of unique input tokens:', num_encoder_tokens)
print('Number of unique output tokens:', num_decoder_tokens)
print('Max sequence length for inputs:', max_encoder_seq_length)
print('Max sequence length for outputs:', max_decoder_seq_length)
input_token_index = dict(
[(char, i) for i, char in enumerate(input_characters)])
target_token_index = dict(
[(char, i) for i, char in enumerate(target_characters)])
encoder_input_data = np.zeros(
(len(input_texts), max_encoder_seq_length, num_encoder_tokens),
dtype='float32')
decoder_input_data = np.zeros(
(len(input_texts), max_decoder_seq_length, num_decoder_tokens),
dtype='float32')
decoder_target_data = np.zeros(
(len(input_texts), max_decoder_seq_length, num_decoder_tokens),
dtype='float32')
for i, (input_text, target_text) in enumerate(zip(input_texts, target_texts)):
for t, char in enumerate(input_text):
encoder_input_data[i, t, input_token_index[char]] = 1.
for t, char in enumerate(target_text):
# decoder_target_data is ahead of decoder_input_data by one timestep
decoder_input_data[i, t, target_token_index[char]] = 1.
if t > 0:
# decoder_target_data will be ahead by one timestep
# and will not include the start character.
decoder_target_data[i, t - 1, target_token_index[char]] = 1.
# Define an input sequence and process it.
encoder_inputs = Input(shape=(None, num_encoder_tokens))
encoder = LSTM(latent_dim, return_state=True)
encoder_outputs, state_h, state_c = encoder(encoder_inputs)
# We discard `encoder_outputs` and only keep the states.
encoder_states = [state_h, state_c]
# Set up the decoder, using `encoder_states` as initial state.
decoder_inputs = Input(shape=(None, num_decoder_tokens))
# We set up our decoder to return full output sequences,
# and to return internal states as well. We don't use the
# return states in the training model, but we will use them in inference.
decoder_lstm = LSTM(latent_dim, return_sequences=True, return_state=True)
decoder_outputs, _, _ = decoder_lstm(decoder_inputs,
initial_state=encoder_states)
decoder_dense = Dense(num_decoder_tokens, activation='softmax')
decoder_outputs = decoder_dense(decoder_outputs)
# Define the model that will turn
# `encoder_input_data` & `decoder_input_data` into `decoder_target_data`
model = Model([encoder_inputs, decoder_inputs], decoder_outputs)
# Run training
model.compile(optimizer='rmsprop', loss='categorical_crossentropy')
model.summary()
hist = model.fit([encoder_input_data, decoder_input_data], decoder_target_data,
batch_size=batch_size, epochs=epochs, validation_split=0.2)
# Save model
model.save('s2s.h5')
# Next: inference mode (sampling).
# Here's the drill:
# 1) encode input and retrieve initial decoder state
# 2) run one step of decoder with this initial state
# and a "start of sequence" token as target.
# Output will be the next target token
# 3) Repeat with the current target token and current states
# Define sampling models
encoder_model = Model(encoder_inputs, encoder_states)
decoder_state_input_h = Input(shape=(latent_dim,))
decoder_state_input_c = Input(shape=(latent_dim,))
decoder_states_inputs = [decoder_state_input_h, decoder_state_input_c]
decoder_outputs, state_h, state_c = decoder_lstm(
decoder_inputs, initial_state=decoder_states_inputs)
decoder_states = [state_h, state_c]
decoder_outputs = decoder_dense(decoder_outputs)
decoder_model = Model(
[decoder_inputs] + decoder_states_inputs,
[decoder_outputs] + decoder_states)
# Reverse-lookup token index to decode sequences back to
# something readable.
reverse_input_char_index = dict(
(i, char) for char, i in input_token_index.items())
reverse_target_char_index = dict(
(i, char) for char, i in target_token_index.items())
def decode_sequence(input_seq):
# Encode the input as state vectors.
states_value = encoder_model.predict(input_seq)
# Generate empty target sequence of length 1.
target_seq = np.zeros((1, 1, num_decoder_tokens))
# Populate the first character of target sequence with the start character.
target_seq[0, 0, target_token_index['\t']] = 1.
# Sampling loop for a batch of sequences
# (to simplify, here we assume a batch of size 1).
stop_condition = False
decoded_sentence = ''
while not stop_condition:
output_tokens, h, c = decoder_model.predict(
[target_seq] + states_value)
# Sample a token
sampled_token_index = np.argmax(output_tokens[0, -1, :])
sampled_char = reverse_target_char_index[sampled_token_index]
decoded_sentence += sampled_char
# Exit condition: either hit max length
# or find stop character.
if (sampled_char == '\n' or
len(decoded_sentence) > max_decoder_seq_length):
stop_condition = True
# Update the target sequence (of length 1).
target_seq = np.zeros((1, 1, num_decoder_tokens))
target_seq[0, 0, sampled_token_index] = 1.
# Update states
states_value = [h, c]
return decoded_sentence
def main():
for seq_index in range(10):
# Take one sequence (part of the training set)
# for trying out decoding.
input_seq = encoder_input_data[seq_index: seq_index + 1]
decoded_sentence = decode_sequence(input_seq)
print('-')
print('Input sentence:', input_texts[seq_index])
print('Decoded sentence:', decoded_sentence)
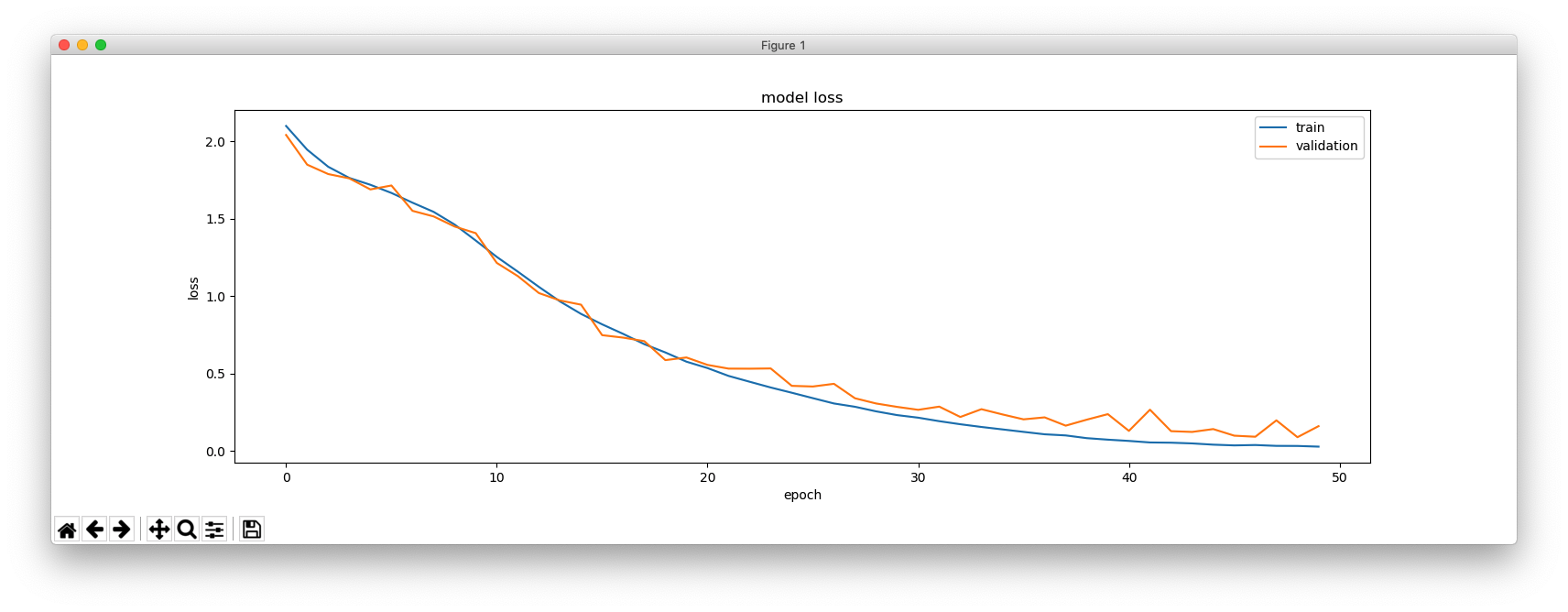
print(hist.history.keys())
plt.figure(figsize=(16, 5))
plt.plot(hist.history['loss'])
plt.plot(hist.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'validation'], loc='upper right')
plt.show()
main()
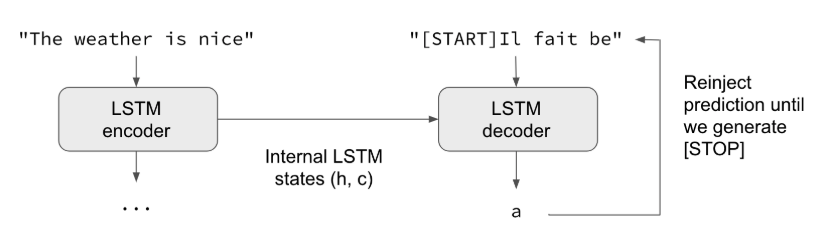
これは、Kerasのサンプルコードです。英語の文を仏語に翻訳します。
英語と仏語の文のペアを用いて、モデルをトレーニングします。
Is she Japanese? Est-elle japonaise ? Is she a doctor? Est-elle médecin ?
私のMac miniで1時間ほどすると、このような結果が得られます。
Input sentence: Be nice. Decoded sentence: Soyez gentil ! - Input sentence: Drop it! Decoded sentence: Laissez tomber ! - Input sentence: Get out! Decoded sentence: Sortez !
ここまでは、良いですね。しかしながら、私たちが本当に知りたいのは、以下のようなトレーニング系列を与えた時に何が起きるかです。
a, .-
aa, .- .-
aal, .- .- .-..
aalii, .- .- .-.. .. ..
(many lines deleted)
antidivorce, .- -. - .. -.. .. ...- --- .-. -.-. .
antidogmatic, .- -. - .. -.. --- --. -- .- - .. -.-.
antidomestic, .- -. - .. -.. --- -- . ... - .. -.-.
antidominican, .- -. - .. -.. --- -- .. -. .. -.-. .- -.
しばらく時間が経過したのち(トレーニング系列のサイズによりますが)、このようになります。
Number of samples: 10000 Number of unique input tokens: 26 Number of unique output tokens: 5 Max sequence length for inputs: 23 Max sequence length for outputs: 95 Train on 8000 samples, validate on 2000 samples Epoch 1/100 - Input sentence: abbacy Decoded sentence: .- -... -... .- -.-. -.-- - Input sentence: abbadide Decoded sentence: .- -... -... .- -.. .. -.. . - Input sentence: abbas Decoded sentence: .- -... -... .- ... Process finished with exit code 0
この特定の例では、トレーニング系列に含まれるサンプルをデコードしていることに留意してください。
from keras.models import Model
from keras.layers import Input, LSTM, Dense
import numpy as np
batch_size = 64 # Batch size for training.
epochs = 100 # Number of epochs to train for.
latent_dim = 256 # Latent dimensionality of the encoding space.
num_samples = 10000 # Number of samples to train on.
# num_samples = 5
data_path = 'seq2seq.txt'
data_path = 'words_morse.txt'
# Vectorize the data.
input_texts = []
target_texts = []
input_characters = set()
target_characters = set()
with open(data_path, 'r', encoding='utf-8') as f:
lines = f.read().split('\n')
for line in lines[: min(num_samples, len(lines) - 1)]:
# input_text, target_text = line.split('\t')
input_text, target_text = line.split(', ')
print("input_text [", input_text, "]", sep="")
print("target_text [", target_text, "]", sep="")
# We use "tab" as the "start sequence" character
# for the targets, and "\n" as "end sequence" character.
target_text = '\t' + target_text + '\n'
input_texts.append(input_text)
target_texts.append(target_text)
for char in input_text:
if char not in input_characters:
input_characters.add(char)
for char in target_text:
if char not in target_characters:
target_characters.add(char)
input_characters = sorted(list(input_characters))
target_characters = sorted(list(target_characters))
num_encoder_tokens = len(input_characters)
num_decoder_tokens = len(target_characters)
max_encoder_seq_length = max([len(txt) for txt in input_texts])
max_decoder_seq_length = max([len(txt) for txt in target_texts])
print('Number of samples:', len(input_texts))
print('Number of unique input tokens:', num_encoder_tokens)
print('Number of unique output tokens:', num_decoder_tokens)
print('Max sequence length for inputs:', max_encoder_seq_length)
print('Max sequence length for outputs:', max_decoder_seq_length)
input_token_index = dict(
[(char, i) for i, char in enumerate(input_characters)])
target_token_index = dict(
[(char, i) for i, char in enumerate(target_characters)])
encoder_input_data = np.zeros(
(len(input_texts), max_encoder_seq_length, num_encoder_tokens),
dtype='float32')
decoder_input_data = np.zeros(
(len(input_texts), max_decoder_seq_length, num_decoder_tokens),
dtype='float32')
decoder_target_data = np.zeros(
(len(input_texts), max_decoder_seq_length, num_decoder_tokens),
dtype='float32')
for i, (input_text, target_text) in enumerate(zip(input_texts, target_texts)):
for t, char in enumerate(input_text):
encoder_input_data[i, t, input_token_index[char]] = 1.
for t, char in enumerate(target_text):
# decoder_target_data is ahead of decoder_input_data by one timestep
decoder_input_data[i, t, target_token_index[char]] = 1.
if t > 0:
# decoder_target_data will be ahead by one timestep
# and will not include the start character.
decoder_target_data[i, t - 1, target_token_index[char]] = 1.
# Define an input sequence and process it.
encoder_inputs = Input(shape=(None, num_encoder_tokens))
encoder = LSTM(latent_dim, return_state=True)
encoder_outputs, state_h, state_c = encoder(encoder_inputs)
# We discard `encoder_outputs` and only keep the states.
encoder_states = [state_h, state_c]
# Set up the decoder, using `encoder_states` as initial state.
decoder_inputs = Input(shape=(None, num_decoder_tokens))
# We set up our decoder to return full output sequences,
# and to return internal states as well. We don't use the
# return states in the training model, but we will use them in inference.
decoder_lstm = LSTM(latent_dim, return_sequences=True, return_state=True)
decoder_outputs, _, _ = decoder_lstm(decoder_inputs,
initial_state=encoder_states)
decoder_dense = Dense(num_decoder_tokens, activation='softmax')
decoder_outputs = decoder_dense(decoder_outputs)
# Define the model that will turn
# `encoder_input_data` & `decoder_input_data` into `decoder_target_data`
model = Model([encoder_inputs, decoder_inputs], decoder_outputs)
# Run training
model.compile(optimizer='rmsprop', loss='categorical_crossentropy')
model.fit([encoder_input_data, decoder_input_data], decoder_target_data,
batch_size=batch_size,
epochs=epochs,
validation_split=0.2)
# Save model
model.save('s2s.h5')
# Next: inference mode (sampling).
# Here's the drill:
# 1) encode input and retrieve initial decoder state
# 2) run one step of decoder with this initial state
# and a "start of sequence" token as target.
# Output will be the next target token
# 3) Repeat with the current target token and current states
# Define sampling models
encoder_model = Model(encoder_inputs, encoder_states)
decoder_state_input_h = Input(shape=(latent_dim,))
decoder_state_input_c = Input(shape=(latent_dim,))
decoder_states_inputs = [decoder_state_input_h, decoder_state_input_c]
decoder_outputs, state_h, state_c = decoder_lstm(
decoder_inputs, initial_state=decoder_states_inputs)
decoder_states = [state_h, state_c]
decoder_outputs = decoder_dense(decoder_outputs)
decoder_model = Model(
[decoder_inputs] + decoder_states_inputs,
[decoder_outputs] + decoder_states)
# Reverse-lookup token index to decode sequences back to
# something readable.
reverse_input_char_index = dict(
(i, char) for char, i in input_token_index.items())
reverse_target_char_index = dict(
(i, char) for char, i in target_token_index.items())
def decode_sequence(input_seq):
# Encode the input as state vectors.
states_value = encoder_model.predict(input_seq)
# Generate empty target sequence of length 1.
target_seq = np.zeros((1, 1, num_decoder_tokens))
# Populate the first character of target sequence with the start character.
target_seq[0, 0, target_token_index['\t']] = 1.
# Sampling loop for a batch of sequences
# (to simplify, here we assume a batch of size 1).
stop_condition = False
decoded_sentence = ''
while not stop_condition:
output_tokens, h, c = decoder_model.predict(
[target_seq] + states_value)
# Sample a token
sampled_token_index = np.argmax(output_tokens[0, -1, :])
sampled_char = reverse_target_char_index[sampled_token_index]
decoded_sentence += sampled_char
# Exit condition: either hit max length
# or find stop character.
if (sampled_char == '\n' or
len(decoded_sentence) > max_decoder_seq_length):
stop_condition = True
# Update the target sequence (of length 1).
target_seq = np.zeros((1, 1, num_decoder_tokens))
target_seq[0, 0, sampled_token_index] = 1.
# Update states
states_value = [h, c]
return decoded_sentence
def main():
for seq_index in range(100):
# Take one sequence (part of the training set)
# for trying out decoding.
input_seq = encoder_input_data[seq_index: seq_index + 1]
decoded_sentence = decode_sequence(input_seq)
print('-')
print('Input sentence:', input_texts[seq_index])
print('Decoded sentence:', decoded_sentence)
main()
また別のタイプのトレーニングシーケンスは、こんな感じです。
a, 10111000
a, 10111000
aa, 1011100010111000
(many lines deleted)
zythia, 111011101010001110101110111000111000101010100010100010111000
zythum, 111011101010001110101110111000111000101010100010101110001110111000
zyzomys, 11101110101000111010111011100011101110101000111011101110001110111000111010111011100010101000
zyzzogeton, 11101110101000111010111011100011101110101000111011101010001110111011100011101110100010001110001110111011100011101000
“000”は、文字間のスペースを表しています。
11101011101000111011101110001110101110100010111000 coca coca 1110101110100010111000101010001000 case case 111010111010001011100010111010001110101000 card card 101010001011101110001010001110111000 swim swim 11101110100010111000101011101000101011101000 gaff gaff 11101011101000101110001010111010001010101000 cafh caln 1010101000101000111010001110101000 hind hind
さらに、別のタイプです。
a, 1 111
aa, 1 111 1 111
aal, 1 111 1 111 1 111 1 1
aalii, 1 111 1 111 1 111 1 1 1 1 1 1
(many lines deleted)
zythia, 111 111 1 1 111 1 111 111 111 1 1 1 1 1 1 1 111
zythum, 111 111 1 1 111 1 111 111 111 1 1 1 1 1 1 111 111 111
zyzomys, 111 111 1 1 111 1 111 111 111 111 1 1 111 111 111 111 111 111 1 111 111 1 1 1
zyzzogeton, 111 111 1 1 111 1 111 111 111 111 1 1 111 111 1 1 111 111 111 111 111 1 1 111 111 111 111 111 1
この方が、あなたには読みやすいですか。
1 1 111 1 1 1 111 1 1 111 111 111 fido fido 1 111 111 1 1 1 111 1 1 adai adai 1 111 1 1 111 111 1 1 1 111 rada rada 1 111 1 111 1 1 1 111 111 alem alem 1 111 111 1 1 1 111 1 111 1 1 pice pice 1 111 111 1 111 111 1 111 1 111 111 eggy egcy 1 111 111 1 1 111 1 111 1 1 1 pale pale
以下の例では、4文字未満の単語も含まれています。
1 111 1 1 ai ai 111 1 111 111 111 111 111 1 1 111 you you 111 1 1 111 111 1 1 111 tutu tutu 1 1 111 1 111 111 111 111 1 1 111 111 1 111 111 foxy foxy 1 1 1 1 111 111 111 111 1 1 hoti hott 111 1 111 1 1 1 111 111 1 1 111 cepa cepa 111 111 1 1 1 111 111 gut gut
from keras.models import Sequential
from keras import layers
import numpy as np
import matplotlib.pyplot as plt
class CharTable(object):
def __init__(self, chars):
self.chars = sorted(set(chars))
self.char_indices = dict((c, i) for i, c in enumerate(self.chars))
self.indices_char = dict((i, c) for i, c in enumerate(self.chars))
def encode(self, token, num_rows):
x = np.zeros((num_rows, len(self.chars)))
for i, c in enumerate(token):
x[i, self.char_indices] = 1
return x
def decode(self, x, calc_argmax=True):
if calc_argmax:
x = [x.argmax(axis=-1)]
return ''.join(self.indices_char[int(v)] for v in x)
def main():
word_len = 4
max_len_x = 15 * word_len + 2*(word_len - 1)
max_len_y = word_len
input_list = []
output_list = []
fin = 'words_morse1only.txt'
with open(fin, 'r') as file:
for line in file.read().splitlines():
mylist = line.split(", ")
[word, morse] = mylist
morse = morse + ' ' * (max_len_x - len(morse))
if len(word) <= word_len:
word = word + ' ' * (word_len - len(word))
input_list.append(morse)
output_list.append(word)
print("input_list = ", input_list[:5])
print("output_list = ", output_list[:5])
# chars_in = '10 '
chars_in = '1 '
chars_out = 'abcdefghijklmnopqrstuvwxyz '
ctable_in = CharTable(chars_in)
ctable_out = CharTable(chars_out)
x = np.zeros((len(input_list), max_len_x, len(chars_in)))
y = np.zeros((len(output_list), max_len_y, len(chars_out)))
for i, token in enumerate(input_list):
x[i] = ctable_in.encode(token, max_len_x)
for i, token in enumerate(output_list):
y[i] = ctable_out.encode(token, max_len_y)
indices = np.arange(len(y))
np.random.shuffle(indices)
x = x[indices]
y = y[indices]
m = len(x) - 100
(x_train, x_val) = x[:m], x[m:]
(y_train, y_val) = y[:m], y[m:]
hidden_size = 64
batch_size = 128
nlayers = 1
epochs = 600
model = Sequential()
model.add(layers.LSTM(hidden_size, input_shape=(max_len_x, len(chars_in))))
model.add(layers.RepeatVector(word_len))
for _ in range(nlayers):
model.add(layers.LSTM(hidden_size, return_sequences=True))
model.add(layers.TimeDistributed(layers.Dense(len(chars_out), activation='softmax')))
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
model.summary()
hist = model.fit(x_train, y_train, batch_size=batch_size,
epochs=epochs, verbose=2, validation_data=(x_val, y_val))
predict = model.predict_classes(x_val)
for i in range(len(x_val)):
print("".join([ctable_in.decode(code) for code in x_val[i]]),
"".join([ctable_out.decode(code) for code in y_val[i]]), end=" ")
for j in range(word_len):
print(ctable_out.indices_char[predict[i][j]], end="")
print()
plt.figure(figsize=(16, 5))
plt.subplot(121)
plt.plot(hist.history['acc'])
plt.plot(hist.history['val_acc'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'validation'], loc='upper left')
plt.subplot(122)
plt.plot(hist.history['loss'])
plt.plot(hist.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'validation'], loc='upper right')
plt.show()
main()
もしも、あなたが現実世界により対応する入力シーケンスを用いることを好むのであれば、1つの方法は、以下のようにトレーニングを行うことです。
a, 101110
aa, 101110 101110
aal, 101110 101110 1011101010
aalii, 101110 101110 1011101010 1010 1010
(many lines deleted)
zythia, 111011101010 11101011101110 1110 10101010 1010 101110
zythum, 111011101010 11101011101110 1110 10101010 10101110 11101110
zyzomys, 111011101010 11101011101110 111011101010 111011101110 11101110 11101011101110 101010
zyzzogeton, 111011101010 11101011101110 111011101010 111011101010 111011101110 1110111010 10 1110 111011101110 111010
ここでは、文字間のスペースシングは完璧に検出され、空白文字で表されていると仮定しています。
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= lstm_1 (LSTM) (None, 128) 67584 _________________________________________________________________ repeat_vector_1 (RepeatVecto (None, 4, 128) 0 _________________________________________________________________ lstm_2 (LSTM) (None, 4, 128) 131584 _________________________________________________________________ time_distributed_1 (TimeDist (None, 4, 27) 3483 ================================================================= Total params: 202,651 Trainable params: 202,651 Non-trainable params: 0 _________________________________________________________________ Train on 4894 samples, validate on 100 samples
10111011101110 10101110 111010111010 1110101110 juck juck 1110101010 10101110 1011101010 1011101010 bull bull 101110111010 1010 1011101010 11101011101110 pily pily 1011101010 10101110 10 101010 lues laes 1110111010 111011101110 1011101110 111010 gown gown 10101010 101110 10101110 1011101010 haul haul 1110 111011101110 1010 1011101010 toil toil
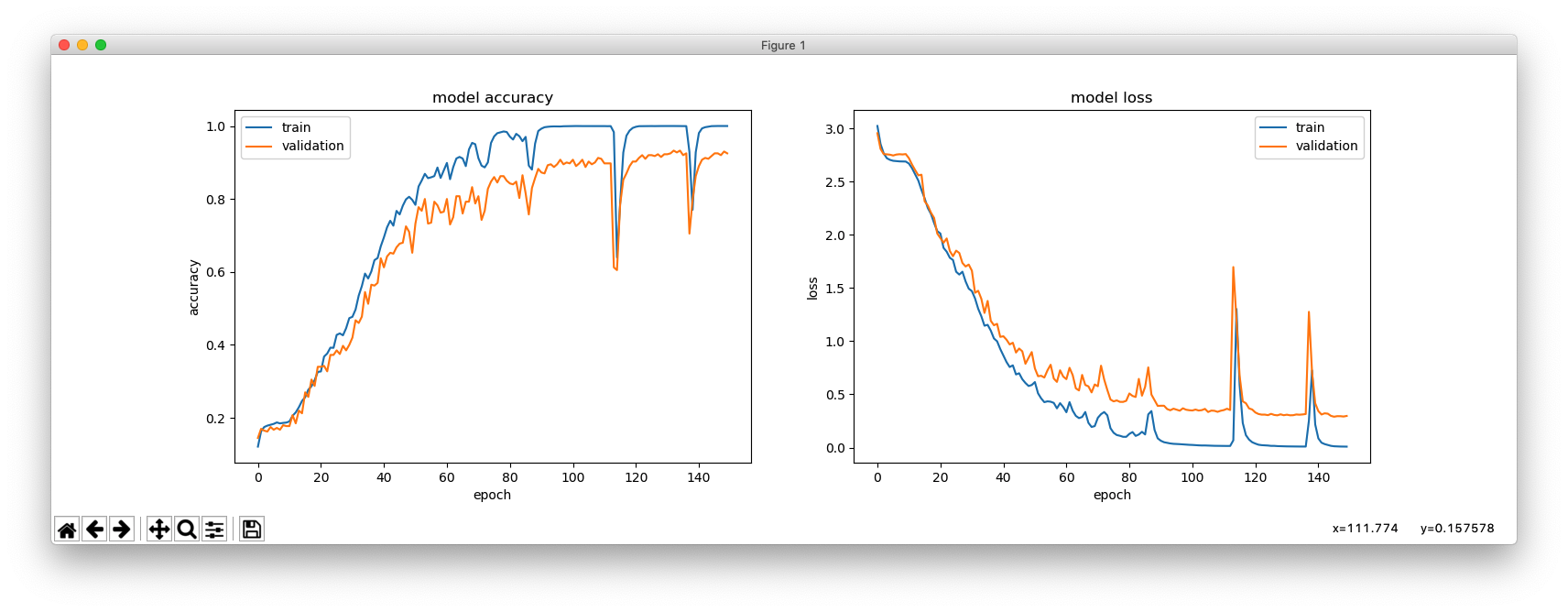
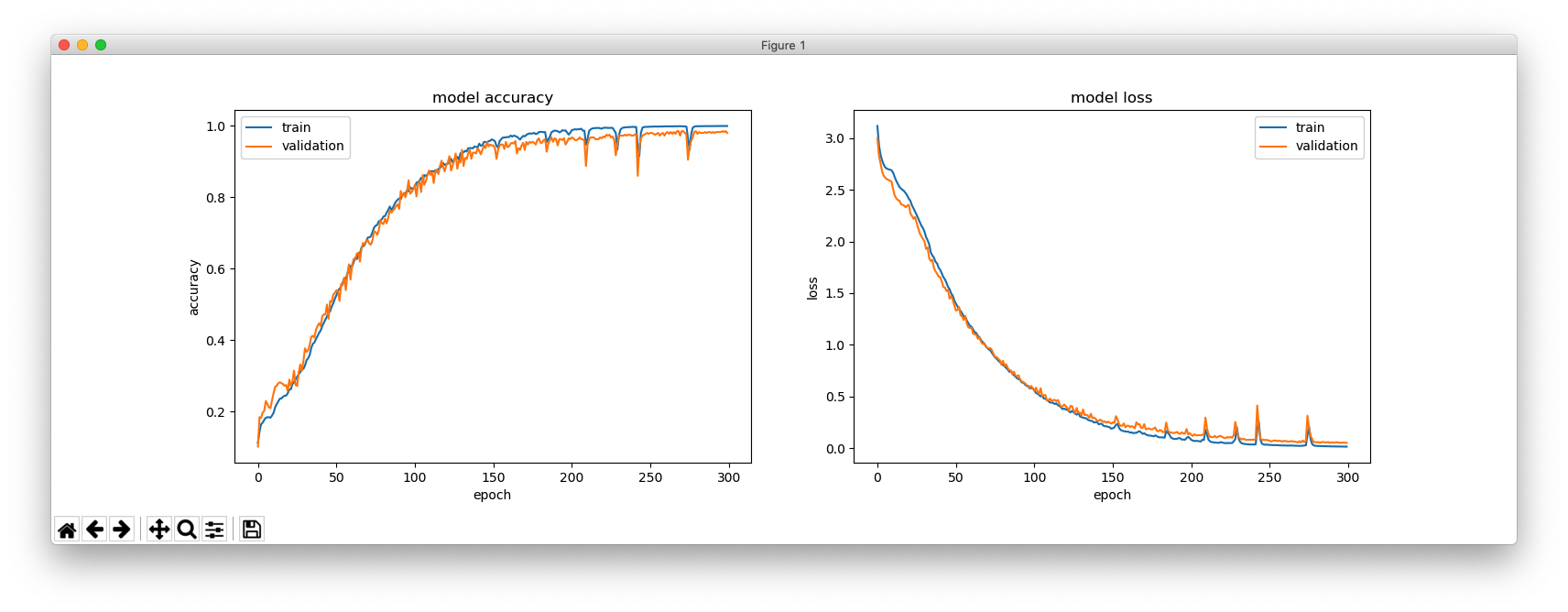
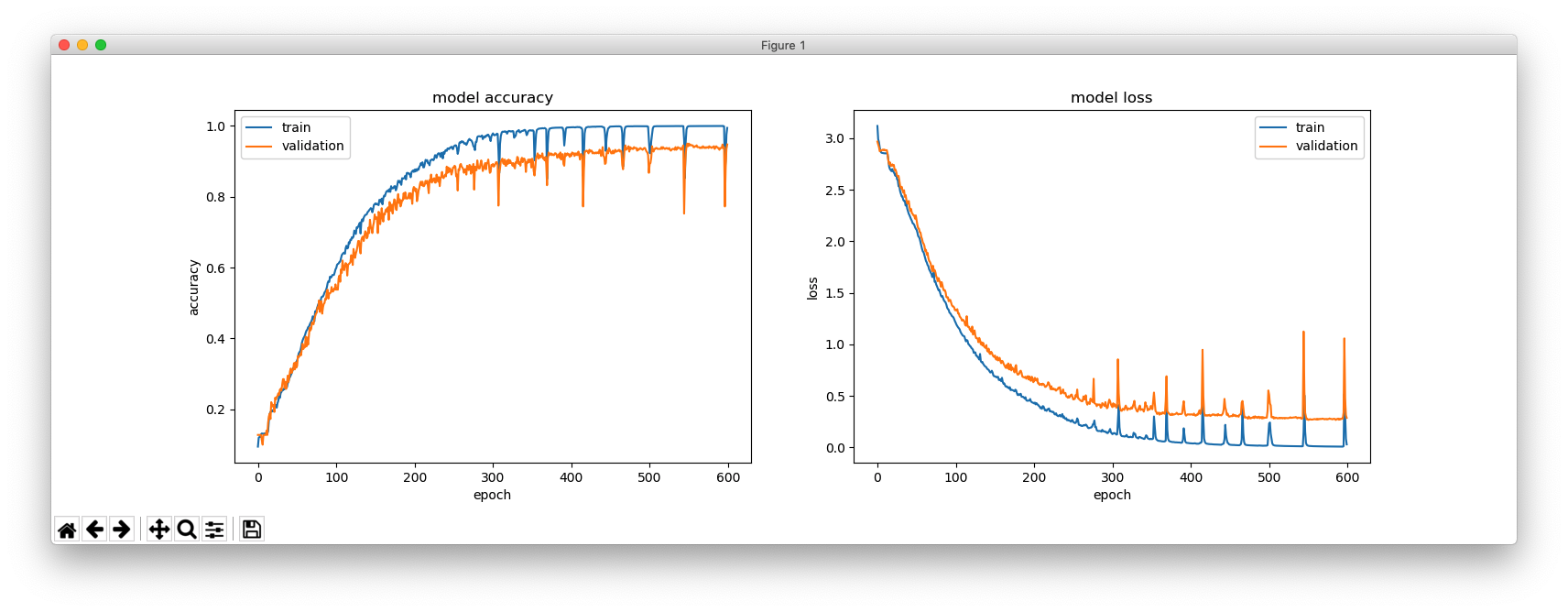
これは、hidden_size = 256 の場合です。
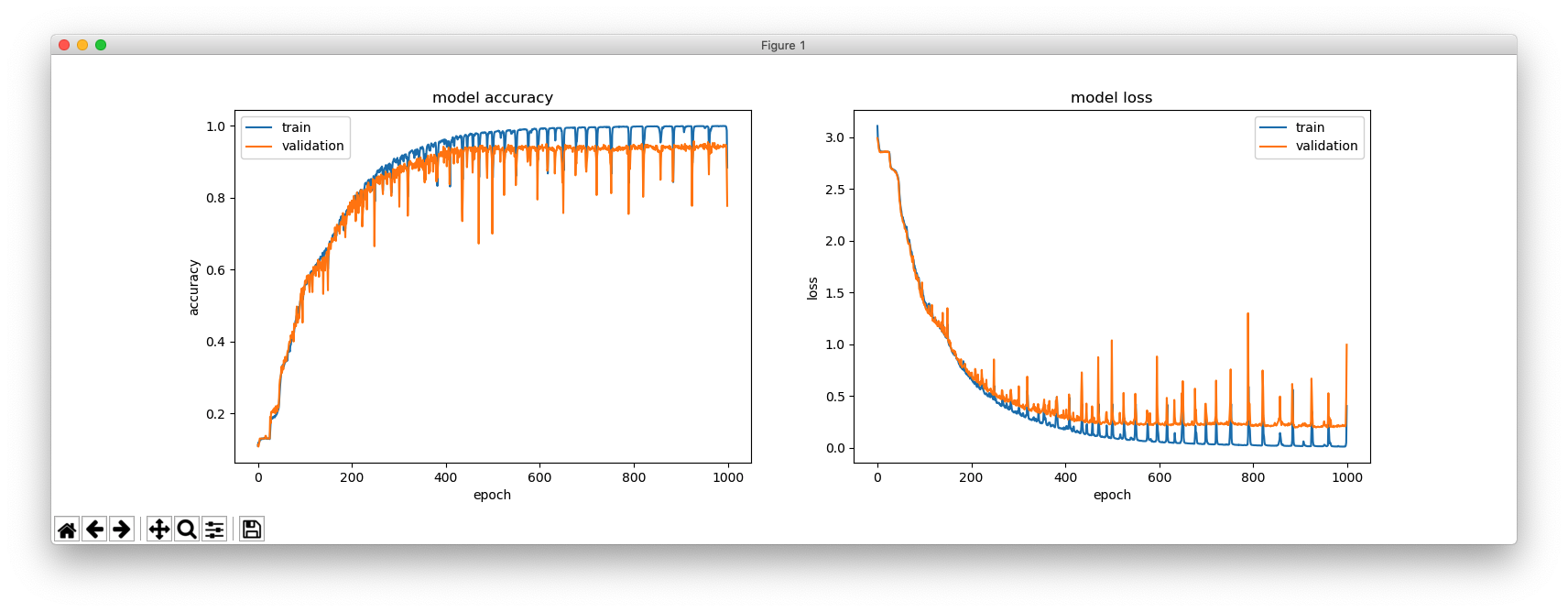
これは、hidden_size = 64 の場合です。
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= lstm_1 (LSTM) (None, 256) 266240 _________________________________________________________________ repeat_vector_1 (RepeatVecto (None, 4, 256) 0 _________________________________________________________________ lstm_2 (LSTM) (None, 4, 256) 525312 _________________________________________________________________ time_distributed_1 (TimeDist (None, 4, 27) 6939 ================================================================= Total params: 798,491 Trainable params: 798,491 Non-trainable params: 0 _________________________________________________________________ Train on 4894 samples, validate on 100 samples
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= lstm_1 (LSTM) (None, 64) 17408 _________________________________________________________________ repeat_vector_1 (RepeatVecto (None, 4, 64) 0 _________________________________________________________________ lstm_2 (LSTM) (None, 4, 64) 33024 _________________________________________________________________ time_distributed_1 (TimeDist (None, 4, 27) 1755 ================================================================= Total params: 52,187 Trainable params: 52,187 Non-trainable params: 0 _________________________________________________________________ Train on 4894 samples, validate on 100 samples
from keras.models import Sequential
from keras import layers
import numpy as np
import matplotlib.pyplot as plt
class CharTable(object):
def __init__(self, chars):
self.chars = sorted(set(chars))
self.char_indices = dict((c, i) for i, c in enumerate(self.chars))
self.indices_char = dict((i, c) for i, c in enumerate(self.chars))
def encode(self, token, num_rows):
x = np.zeros((num_rows, len(self.chars)))
for i, c in enumerate(token):
x[i, self.char_indices] = 1
return x
def decode(self, x, calc_argmax=True):
if calc_argmax:
x = [x.argmax(axis=-1)]
return ''.join(self.indices_char[int(v)] for v in x)
def main():
word_len = 4
max_len_x = 15 * word_len + (word_len - 1)
max_len_y = word_len
input_list = []
output_list = []
fin = 'words_morse10.txt'
with open(fin, 'r') as file:
for line in file.read().splitlines():
mylist = line.split(", ")
[word, morse] = mylist
morse = morse + ' ' * (max_len_x - len(morse))
if len(word) == word_len:
input_list.append(morse)
output_list.append(word)
chars_in = '10 '
chars_out = 'abcdefghijklmnopqrstuvwxyz '
ctable_in = CharTable(chars_in)
ctable_out = CharTable(chars_out)
x = np.zeros((len(input_list), max_len_x, len(chars_in)))
y = np.zeros((len(output_list), max_len_y, len(chars_out)))
for i, token in enumerate(input_list):
x[i] = ctable_in.encode(token, max_len_x)
for i, token in enumerate(output_list):
y[i] = ctable_out.encode(token, max_len_y)
indices = np.arange(len(y))
np.random.shuffle(indices)
x = x[indices]
y = y[indices]
m = len(x) - 100
(x_train, x_val) = x[:m], x[m:]
(y_train, y_val) = y[:m], y[m:]
hidden_size = 128
batch_size = 128
nlayers = 1
epochs = 150
model = Sequential()
model.add(layers.LSTM(hidden_size, input_shape=(max_len_x, len(chars_in))))
model.add(layers.RepeatVector(word_len))
for _ in range(nlayers):
model.add(layers.LSTM(hidden_size, return_sequences=True))
model.add(layers.TimeDistributed(layers.Dense(len(chars_out), activation='softmax')))
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
model.summary()
hist = model.fit(x_train, y_train, batch_size=batch_size,
epochs=epochs, verbose=2, validation_data=(x_val, y_val))
predict = model.predict_classes(x_val)
for i in range(len(x_val)):
print("".join([ctable_in.decode(code) for code in x_val[i]]),
"".join([ctable_out.decode(code) for code in y_val[i]]), end=" ")
for j in range(word_len):
print(ctable_out.indices_char[predict[i][j]], end="")
print()
plt.figure(figsize=(16, 5))
plt.subplot(121)
plt.plot(hist.history['acc'])
plt.plot(hist.history['val_acc'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'validation'], loc='upper left')
plt.subplot(122)
plt.plot(hist.history['loss'])
plt.plot(hist.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'validation'], loc='upper right')
plt.show()
main()
import numpy as np
def morse_encode(word):
return " ".join([morse_dict[i]for i in " ".join(word).split()])
def data_gen():
fin = 'words_alpha.txt'
with open(fin, 'r') as file:
for word in file.read().lower().splitlines():
print(word, morse_encode(word), sep=", ")
return
alphabet = list("abcdefghijklmnopqrstuvwxyz")
# values = ['.-', '-...', '-.-.', '-..', '.', '..-.', '--.', '....', '..', '.---', '-.-',
# '.-..', '--', '-.', '---', '.--.', '--.-',
# '.-.', '...', '-', '..-', '...-', '.--', '-..-', '-.--', '--..']
values = ['101110', '1110101010', '111010111010', '11101010', '10', '1010111010',
'1110111010', '10101010', '1010', '10111011101110', '1110101110',
'1011101010', '11101110', '111010', '111011101110', '101110111010',
'11101110101110', '10111010', '101010', '1110', '10101110', '1010101110',
'1011101110', '111010101110', '11101011101110', '111011101010']
morse_dict = dict(zip(alphabet, values))
data_gen()
a, .-
aa, .- .-
aal, .- .- .-..
aalii, .- .- .-.. .. ..
(many lines deleted)
zythia, --.. -.-- - .... .. .-
zythum, --.. -.-- - .... ..- --
zyzomys, --.. -.-- --.. --- -- -.-- ...
zyzzogeton, --.. -.-- --.. --.. --- --. . - --- -.
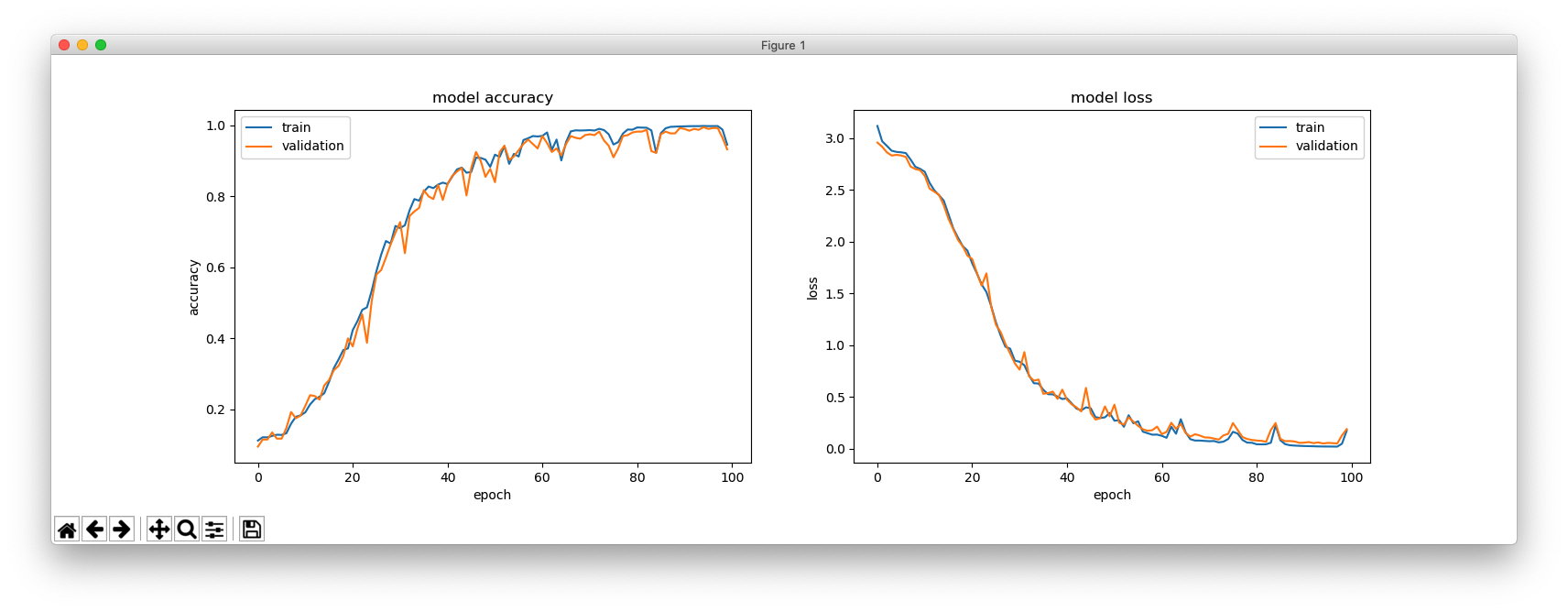
これは、234,369行からなるトレーニング用のシーケンスです。末尾にある短いPythonプログラムで生成しました。
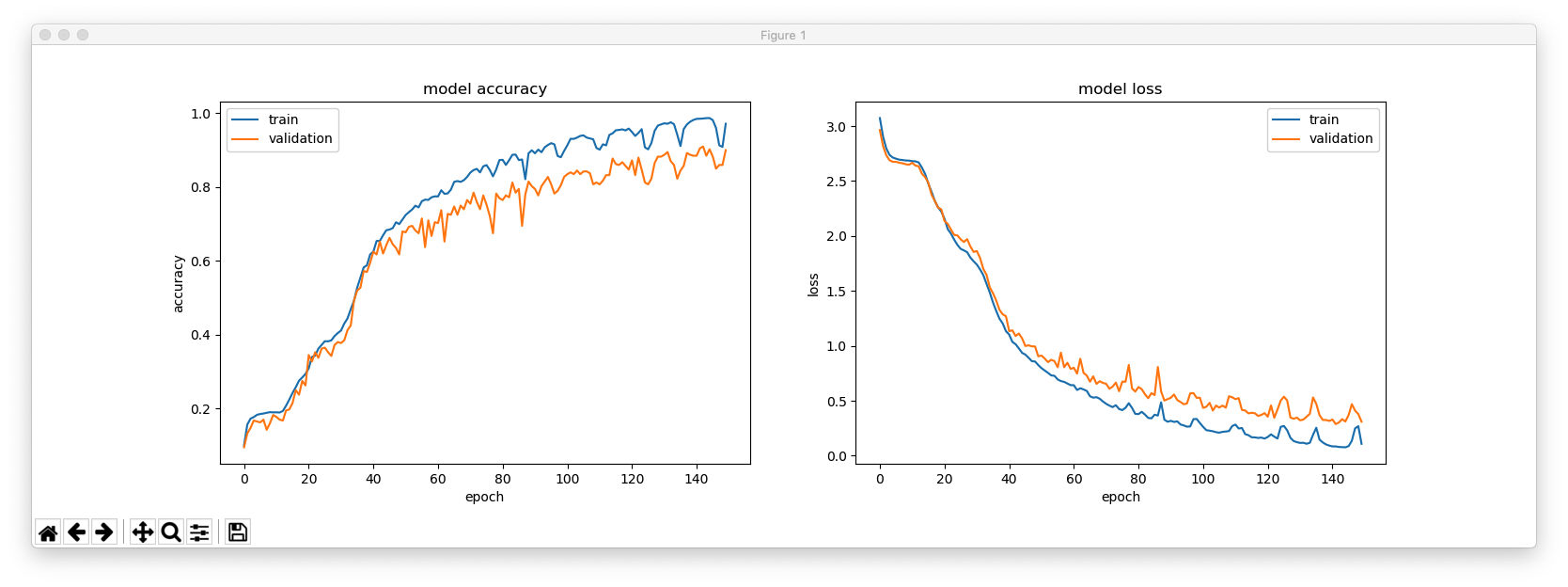
さて、4文字の単語が解読できるか試して見ましょう。
Train on 4894 samples, validate on 100 samples
私たちは、4894+100個のそのような単語を持っています。なので、その中からランダムに100個を選び、トレーニングにはではなく、検証用に使う為に脇に置いておきます。.
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= lstm_1 (LSTM) (None, 128) 67584 _________________________________________________________________ repeat_vector_1 (RepeatVecto (None, 4, 128) 0 _________________________________________________________________ lstm_2 (LSTM) (None, 4, 128) 131584 _________________________________________________________________ lstm_3 (LSTM) (None, 4, 128) 131584 _________________________________________________________________ lstm_4 (LSTM) (None, 4, 128) 131584 _________________________________________________________________ time_distributed_1 (TimeDist (None, 4, 27) 3483 ================================================================= Total params: 465,819 Trainable params: 465,819 Non-trainable params: 0
-.-. --- .--. .- copa copa -.- -.-- .- .... kyah kyah -... .-. .- . brae brae -. .- .-. -.- nark nark .--. .... --- .... phoh phob .- --.. --- -. azon auon -.-. --- ...- . cove cove -... .- .-. .. bari bari -- . .- -.- meak meak -- --- -. --. mong mong -- .- - . mate mate - .... .. .-. thir thir
悪く無いですか?
復号プログラムは、モールス符号の表は持っていないことに注意して下さい。
from keras.models import Sequential
from keras import layers
import numpy as np
import matplotlib.pyplot as plt
class CharTable(object):
def __init__(self, chars):
self.chars = sorted(set(chars))
self.char_indices = dict((c, i) for i, c in enumerate(self.chars))
self.indices_char = dict((i, c) for i, c in enumerate(self.chars))
def encode(self, token, num_rows):
x = np.zeros((num_rows, len(self.chars)))
for i, c in enumerate(token):
x[i, self.char_indices] = 1
return x
def decode(self, x, calc_argmax=True):
if calc_argmax:
x = [x.argmax(axis=-1)]
return ''.join(self.indices_char[int(v)] for v in x)
def main():
word_len = 4
max_len_x = 4 * word_len + (word_len - 1)
max_len_y = word_len
input_list = []
output_list = []
fin = 'words_morse.txt'
with open(fin, 'r') as file:
for line in file.read().splitlines():
mylist = line.split(", ")
[word, morse] = mylist
morse = morse + ' ' * (max_len_x - len(morse))
if len(word) == word_len:
input_list.append(morse)
output_list.append(word)
chars_in = '-. '
chars_out = 'abcdefghijklmnopqrstuvwxyz '
ctable_in = CharTable(chars_in)
ctable_out = CharTable(chars_out)
x = np.zeros((len(input_list), max_len_x, len(chars_in)))
y = np.zeros((len(output_list), max_len_y, len(chars_out)))
for i, token in enumerate(input_list):
x[i] = ctable_in.encode(token, max_len_x)
for i, token in enumerate(output_list):
y[i] = ctable_out.encode(token, max_len_y)
indices = np.arange(len(y))
np.random.shuffle(indices)
x = x[indices]
y = y[indices]
m = len(x) - 100
(x_train, x_val) = x[:m], x[m:]
(y_train, y_val) = y[:m], y[m:]
hidden_size = 128
batch_size = 128
nlayers = 3
epochs = 100
model = Sequential()
model.add(layers.LSTM(hidden_size, input_shape=(max_len_x, len(chars_in))))
model.add(layers.RepeatVector(word_len))
for _ in range(nlayers):
model.add(layers.LSTM(hidden_size, return_sequences=True))
model.add(layers.TimeDistributed(layers.Dense(len(chars_out), activation='softmax')))
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
model.summary()
hist = model.fit(x_train, y_train, batch_size=batch_size,
epochs=epochs, verbose=2, validation_data=(x_val, y_val))
predict = model.predict_classes(x_val)
for i in range(len(x_val)):
print("".join([ctable_in.decode(code) for code in x_val[i]]),
"".join([ctable_out.decode(code) for code in y_val[i]]), end=" ")
for j in range(word_len):
print(ctable_out.indices_char[predict[i][j]], end="")
print()
plt.figure(figsize=(16, 5))
plt.subplot(121)
plt.plot(hist.history['acc'])
plt.plot(hist.history['val_acc'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'validation'], loc='upper left')
plt.subplot(122)
plt.plot(hist.history['loss'])
plt.plot(hist.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'validation'], loc='upper right')
plt.show()
main()
The following program is to generate a training sequence. A morse code table is required only in this program.
import numpy as np
def morse_encode(word):
return " ".join([morse_dict[i]for i in " ".join(word).split()])
def data_gen():
fin = 'words_alpha.txt'
with open(fin, 'r') as file:
for word in file.read().lower().splitlines():
print(word, morse_encode(word), sep=", ")
return
alphabet = list("abcdefghijklmnopqrstuvwxyz")
values = ['.-', '-...', '-.-.', '-..', '.', '..-.', '--.', '....', '..', '.---', '-.-',
'.-..', '--', '-.', '---', '.--.', '--.-',
'.-.', '...', '-', '..-', '...-', '.--', '-..-', '-.--', '--..']
morse_dict = dict(zip(alphabet, values))
data_gen()

1つの簡単な例はこれです:
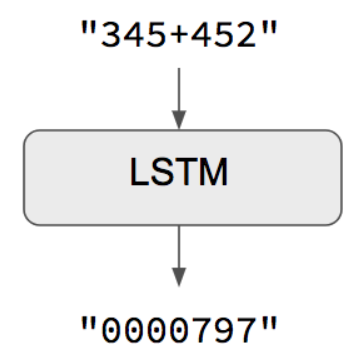
https://keras.io/examples/addition_rnn/
https://blog.keras.io/a-ten-minute-introduction-to-sequence-to-sequence-learning-in-keras.html
LSTMは、Long short-term memoryの略で、recurrent neural network (RNN)の一種です。
ハイパーパラメータを変えて、いくつかの学習曲線が図に示されています。
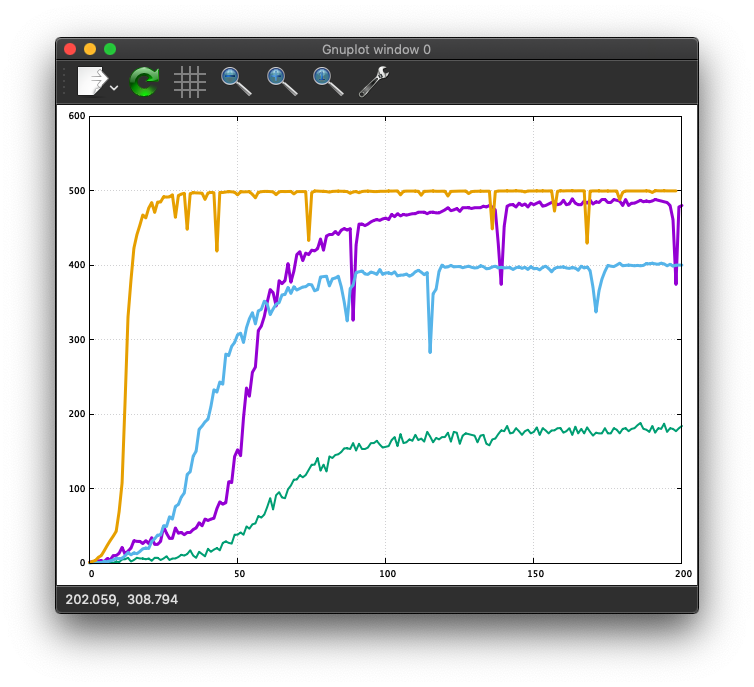
当然のことながら、予測は完璧ではありません。

from keras.models import Sequential
from keras import layers
import numpy as np
from six.moves import range
class CharacterTable(object):
"""Given a set of characters:
+ Encode them to a one-hot integer representation
+ Decode the one-hot or integer representation to their character output
+ Decode a vector of probabilities to their character output
"""
def __init__(self, chars):
"""Initialize character table.
# Arguments
chars: Characters that can appear in the input.
"""
self.chars = sorted(set(chars))
self.char_indices = dict((c, i) for i, c in enumerate(self.chars))
self.indices_char = dict((i, c) for i, c in enumerate(self.chars))
def encode(self, C, num_rows):
"""One-hot encode given string C.
# Arguments
C: string, to be encoded.
num_rows: Number of rows in the returned one-hot encoding. This is
used to keep the # of rows for each data the same.
"""
x = np.zeros((num_rows, len(self.chars)))
for i, c in enumerate(C):
x[i, self.char_indices] = 1
return x
def decode(self, x, calc_argmax=True):
"""Decode the given vector or 2D array to their character output.
# Arguments
x: A vector or a 2D array of probabilities or one-hot representations;
or a vector of character indices (used with `calc_argmax=False`).
calc_argmax: Whether to find the character index with maximum
probability, defaults to `True`.
"""
if calc_argmax:
x = x.argmax(axis=-1)
return ''.join(self.indices_char[x] for x in x)
class colors:
ok = '\033[92m'
fail = '\033[91m'
close = '\033[0m'
# Parameters for the model and dataset.
TRAINING_SIZE = 50000
DIGITS = 3
REVERSE = True
# Maximum length of input is 'int + int' (e.g., '345+678'). Maximum length of
# int is DIGITS.
MAXLEN = DIGITS + 1 + DIGITS
# All the numbers, plus sign and space for padding.
chars = '0123456789+ '
ctable = CharacterTable(chars)
questions = []
expected = []
seen = set()
print('Generating data...')
while len(questions) < TRAINING_SIZE:
f = lambda: int(''.join(np.random.choice(list('0123456789'))
for i in range(np.random.randint(1, DIGITS + 1))))
a, b = f(), f()
# Skip any addition questions we've already seen
# Also skip any such that x+Y == Y+x (hence the sorting).
key = tuple(sorted((a, b)))
if key in seen:
continue
seen.add(key)
# Pad the data with spaces such that it is always MAXLEN.
q = '{}+{}'.format(a, b)
query = q + ' ' * (MAXLEN - len(q))
ans = str(a + b)
# Answers can be of maximum size DIGITS + 1.
ans += ' ' * (DIGITS + 1 - len(ans))
if REVERSE:
# Reverse the query, e.g., '12+345 ' becomes ' 543+21'. (Note the
# space used for padding.)
query = query[::-1]
questions.append(query)
expected.append(ans)
print('Total addition questions:', len(questions))
print('Vectorization...')
x = np.zeros((len(questions), MAXLEN, len(chars)), dtype=np.bool)
y = np.zeros((len(questions), DIGITS + 1, len(chars)), dtype=np.bool)
for i, sentence in enumerate(questions):
x[i] = ctable.encode(sentence, MAXLEN)
for i, sentence in enumerate(expected):
y[i] = ctable.encode(sentence, DIGITS + 1)
# Shuffle (x, y) in unison as the later parts of x will almost all be larger
# digits.
indices = np.arange(len(y))
np.random.shuffle(indices)
x = x[indices]
y = y[indices]
# Explicitly set apart 10% for validation data that we never train over.
split_at = len(x) - len(x) // 10
(x_train, x_val) = x[:split_at], x[split_at:]
(y_train, y_val) = y[:split_at], y[split_at:]
print('Training Data:')
print(x_train.shape)
print(y_train.shape)
print('Validation Data:')
print(x_val.shape)
print(y_val.shape)
# Try replacing GRU, or SimpleRNN.
RNN = layers.LSTM
HIDDEN_SIZE = 128
BATCH_SIZE = 128
LAYERS = 1
print('Build model...')
model = Sequential()
# "Encode" the input sequence using an RNN, producing an output of HIDDEN_SIZE.
# Note: In a situation where your input sequences have a variable length,
# use input_shape=(None, num_feature).
model.add(RNN(HIDDEN_SIZE, input_shape=(MAXLEN, len(chars))))
# As the decoder RNN's input, repeatedly provide with the last output of
# RNN for each time step. Repeat 'DIGITS + 1' times as that's the maximum
# length of output, e.g., when DIGITS=3, max output is 999+999=1998.
model.add(layers.RepeatVector(DIGITS + 1))
# The decoder RNN could be multiple layers stacked or a single layer.
for _ in range(LAYERS):
# By setting return_sequences to True, return not only the last output but
# all the outputs so far in the form of (num_samples, timesteps,
# output_dim). This is necessary as TimeDistributed in the below expects
# the first dimension to be the timesteps.
model.add(RNN(HIDDEN_SIZE, return_sequences=True))
# Apply a dense layer to the every temporal slice of an input. For each of step
# of the output sequence, decide which character should be chosen.
model.add(layers.TimeDistributed(layers.Dense(len(chars), activation='softmax')))
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
model.summary()
# Train the model each generation and show predictions against the validation
# dataset.
for iteration in range(1, 200):
correct_count = 0
error_count = 0
print()
print('- ' * 50)
print('Iteration', iteration)
model.fit(x_train, y_train,
batch_size=BATCH_SIZE,
epochs=1,
validation_data=(x_val, y_val))
# Select 10 samples from the validation set at random so we can visualize
# errors.
for i in range(len(x_val)):
rowx, rowy = x_val[np.array([i])], y_val[np.array([i])]
preds = model.predict_classes(rowx, verbose=0)
q = ctable.decode(rowx[0])
correct = ctable.decode(rowy[0])
guess = ctable.decode(preds[0], calc_argmax=False)
print('Q', q[::-1] if REVERSE else q, end=' ')
print('T', correct, end=' ')
if correct == guess:
print(colors.ok + '☑' + colors.close, end=' ')
correct_count = correct_count + 1
else:
print(colors.fail + '☒' + colors.close, end=' ')
error_count = error_count + 1
print(guess)
print("score = ", correct_count / (correct_count+error_count))