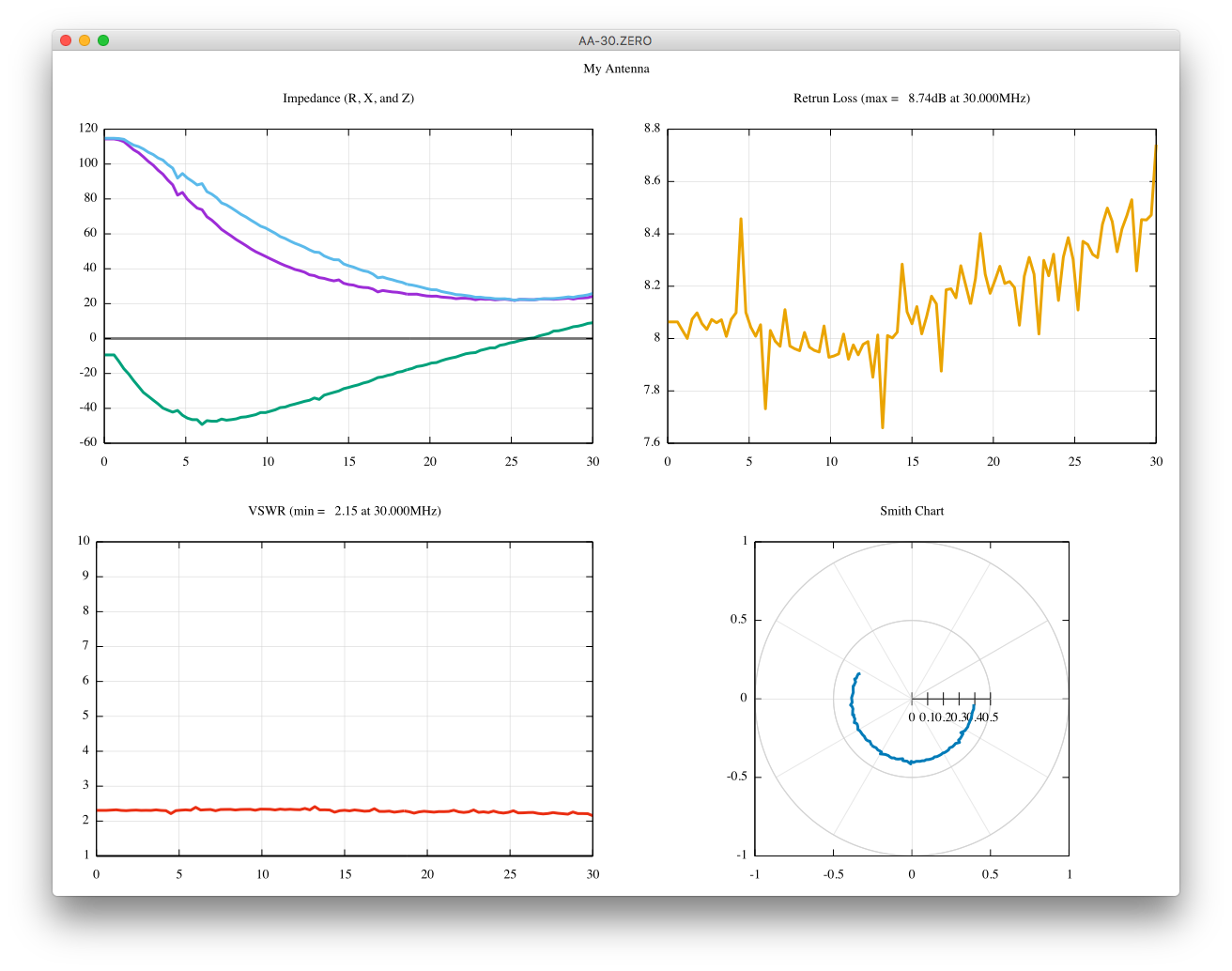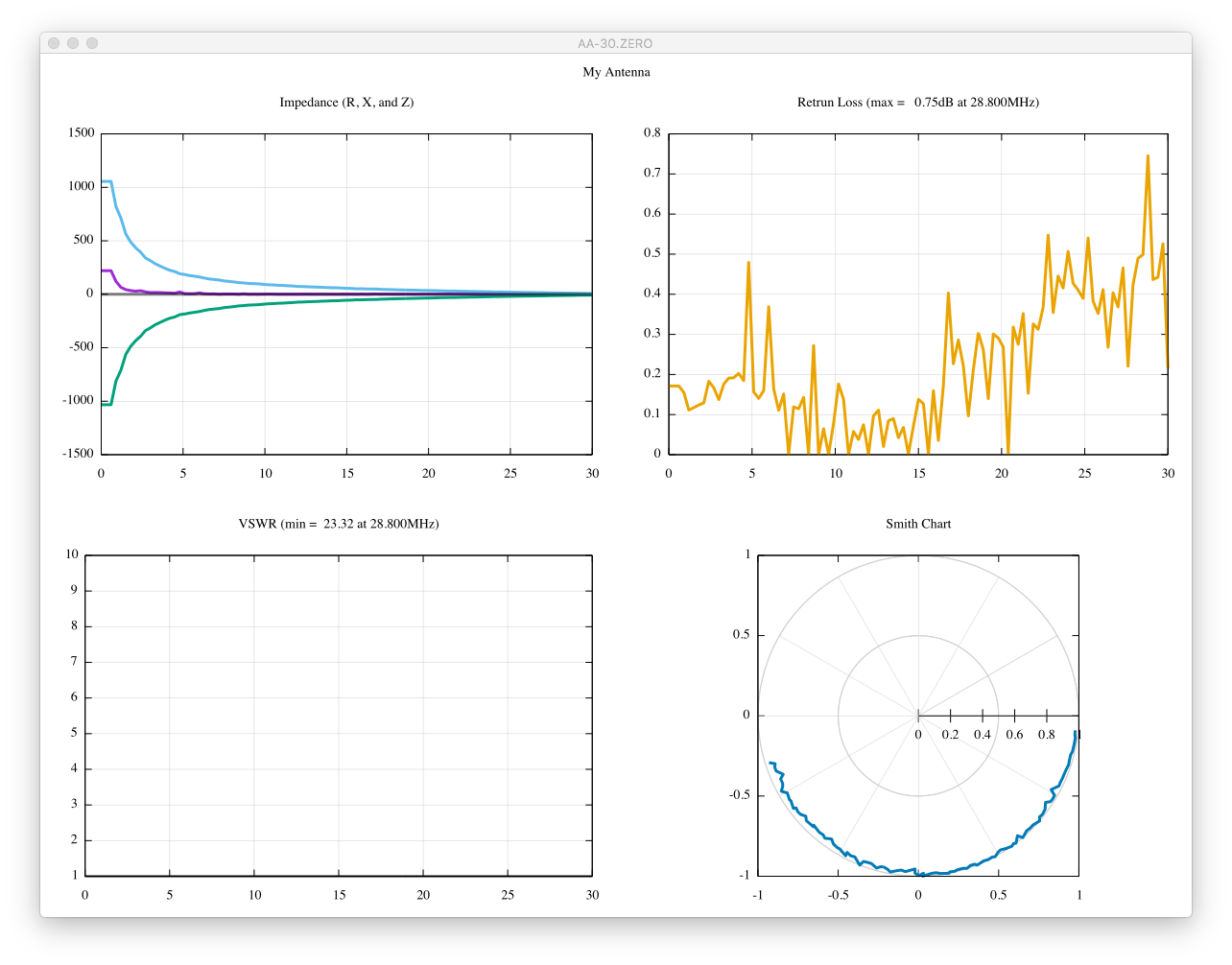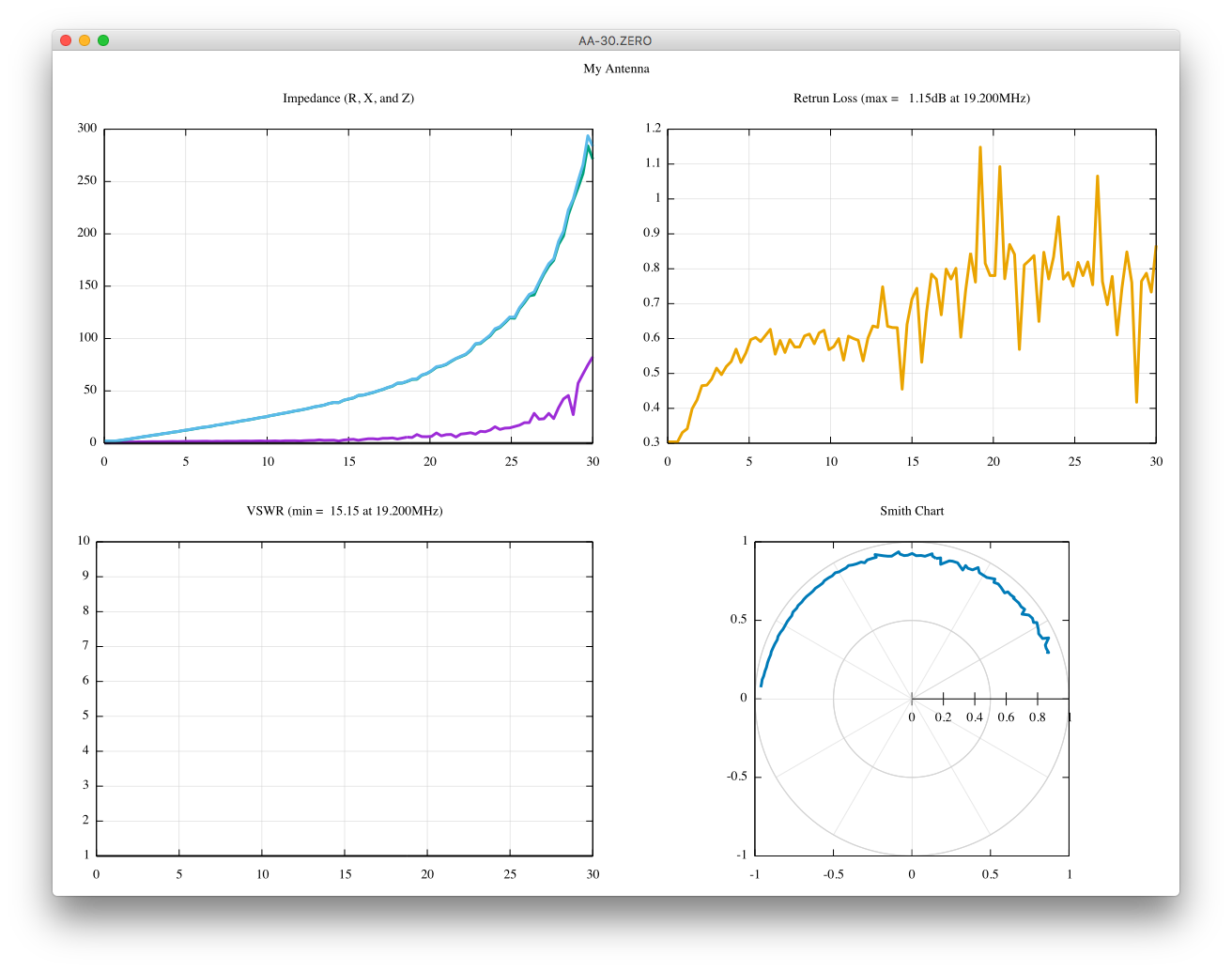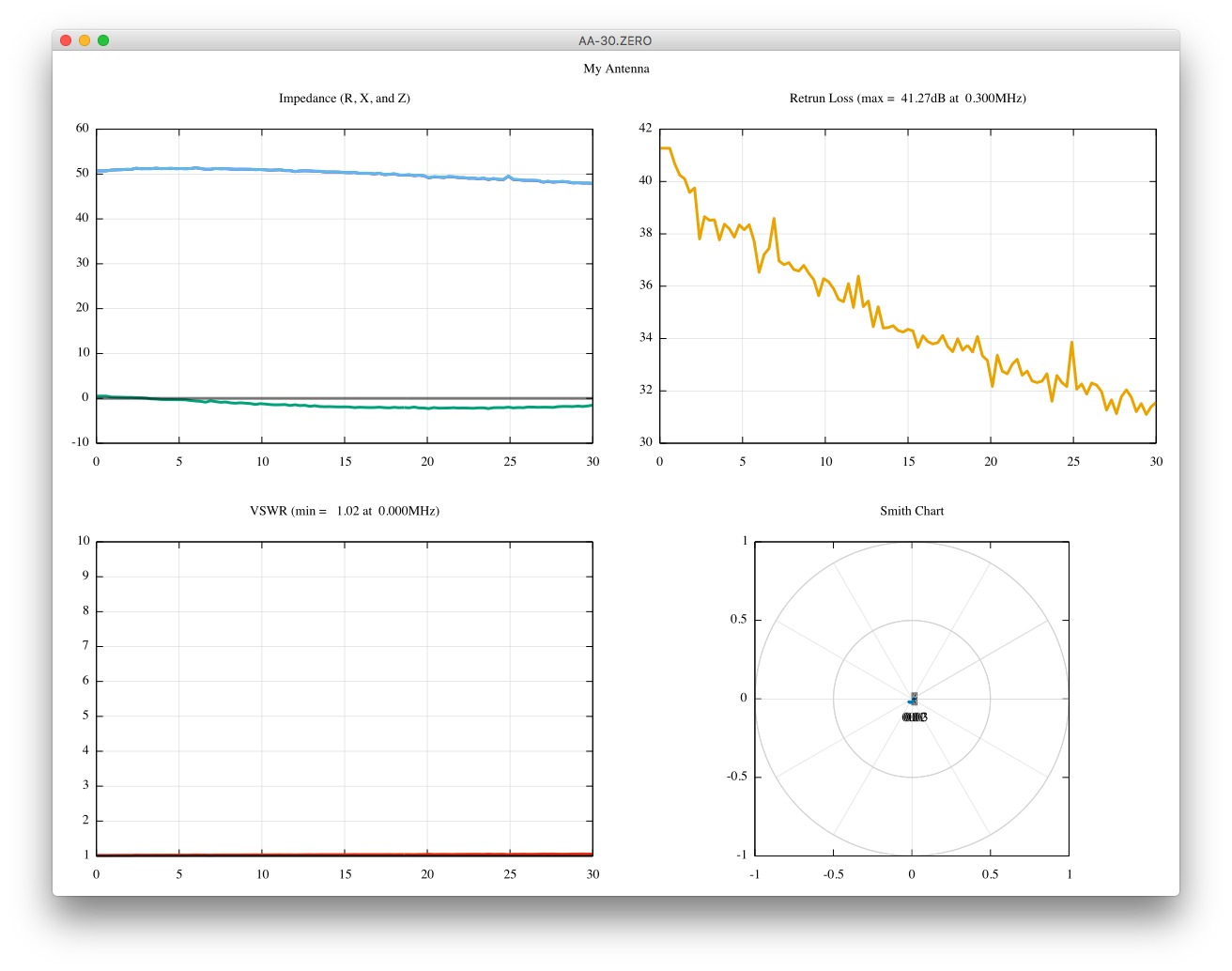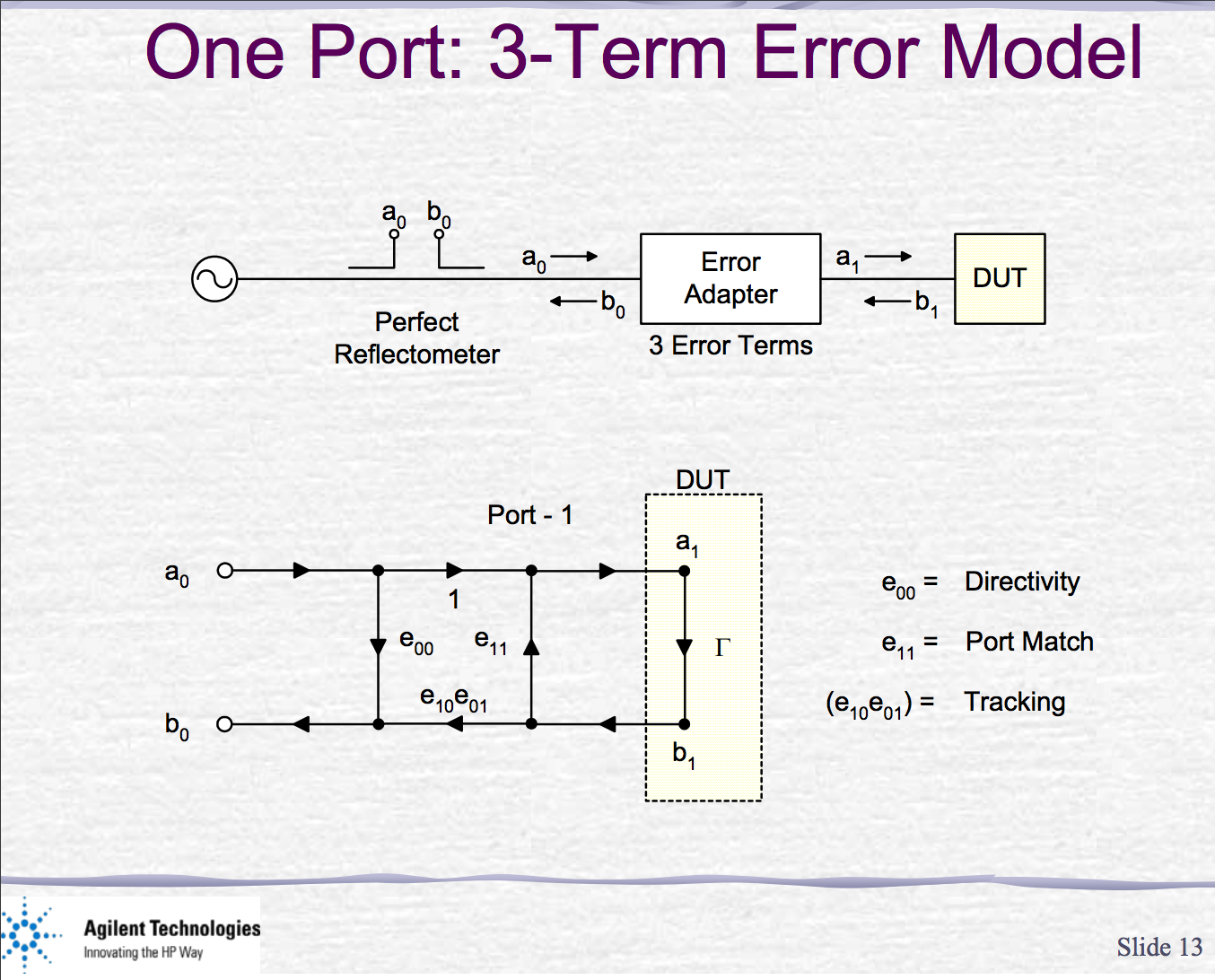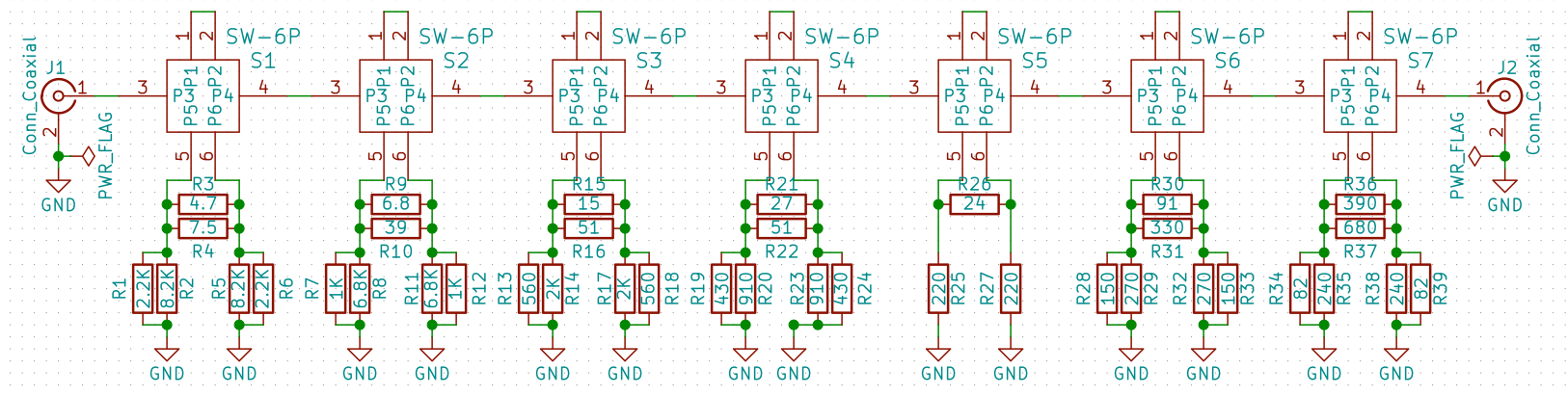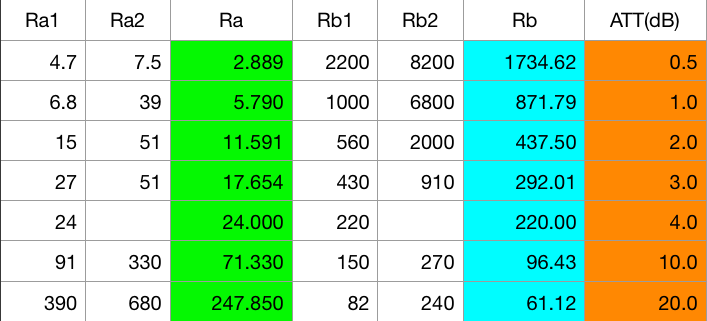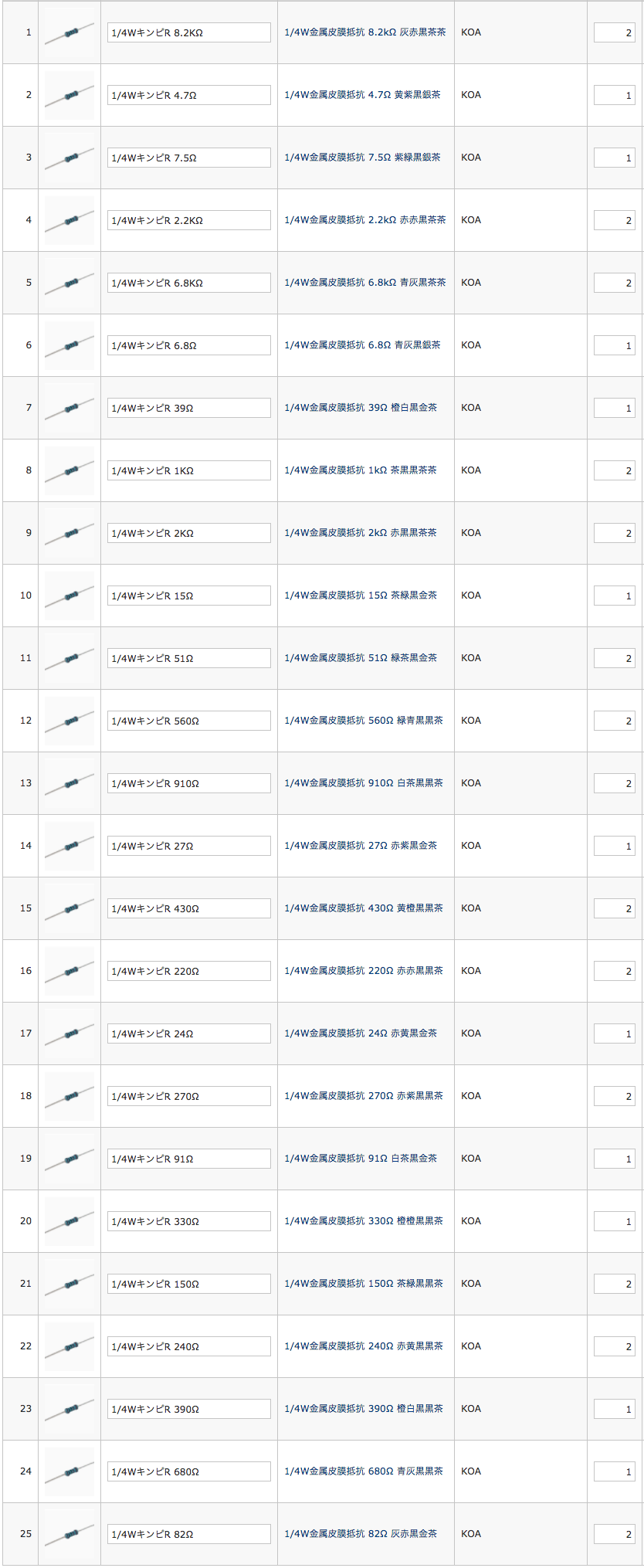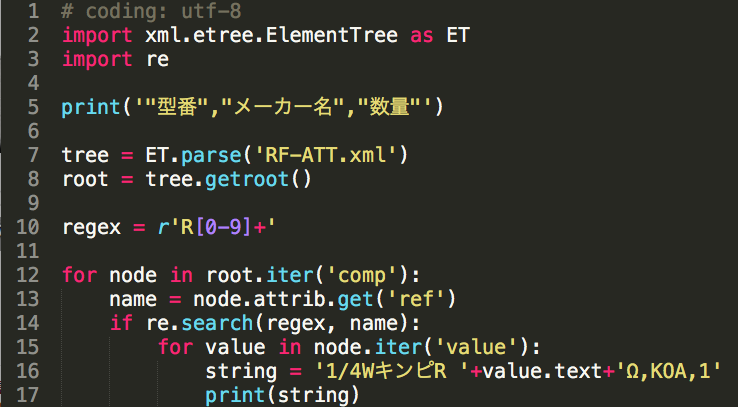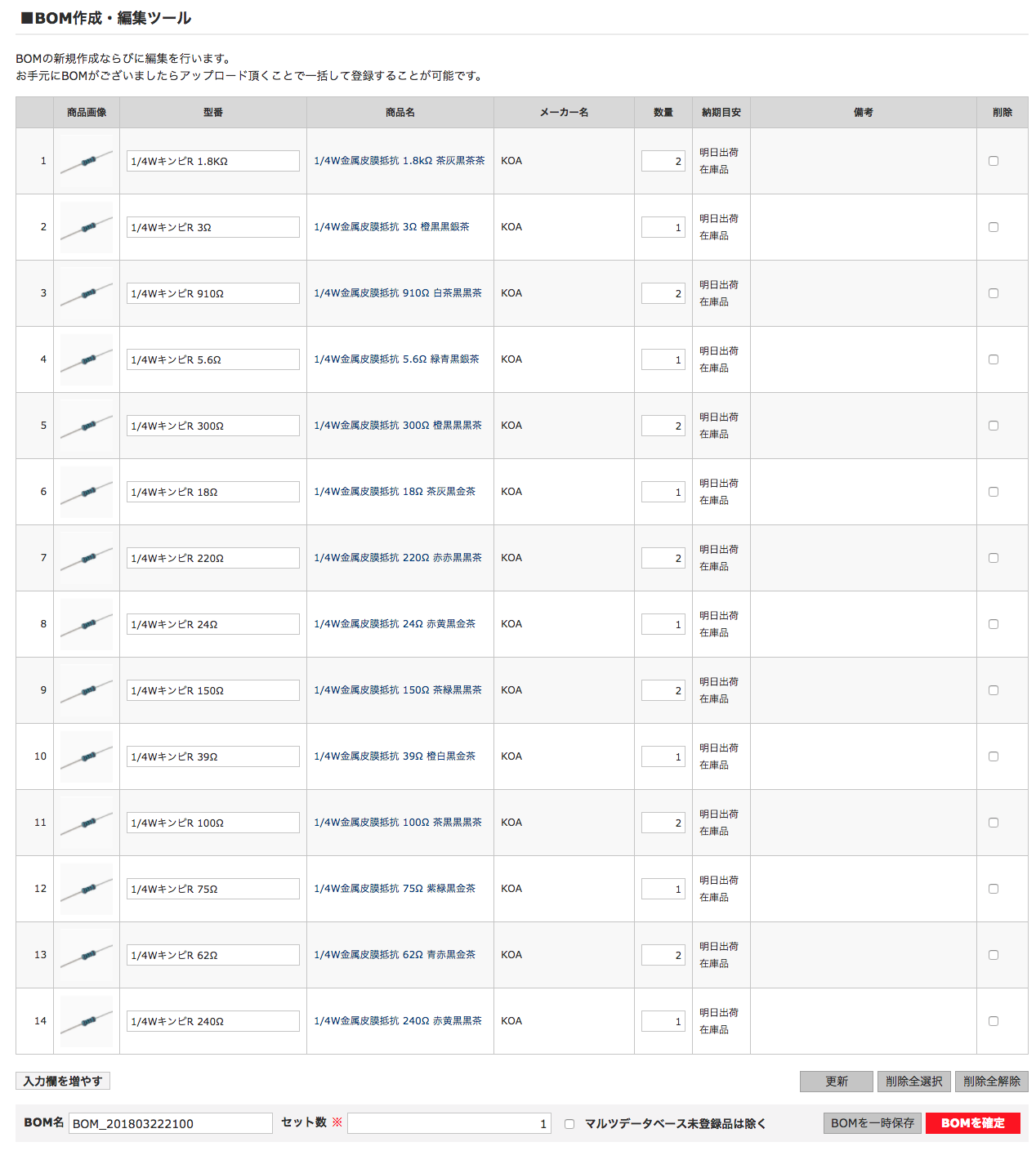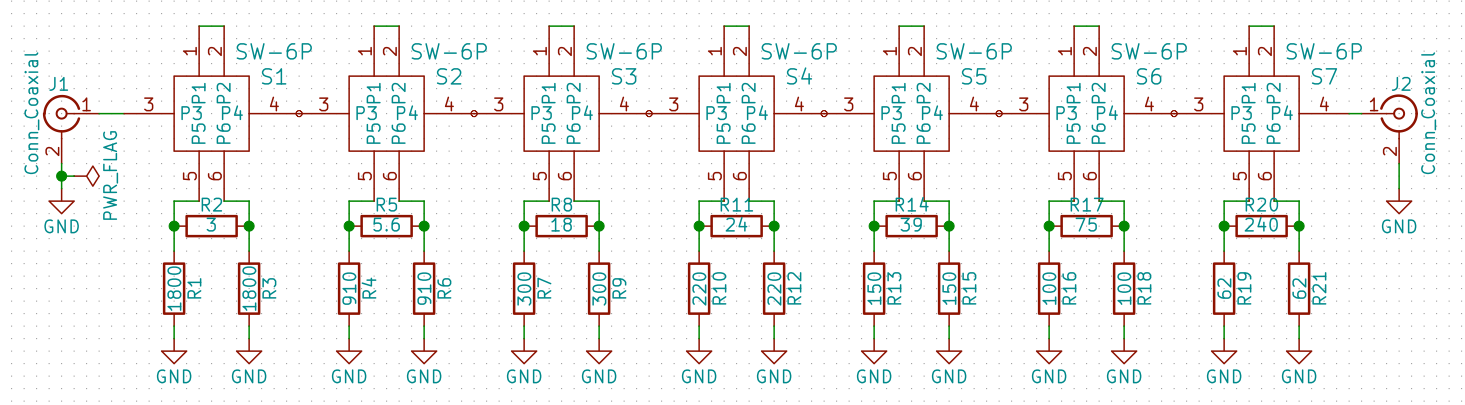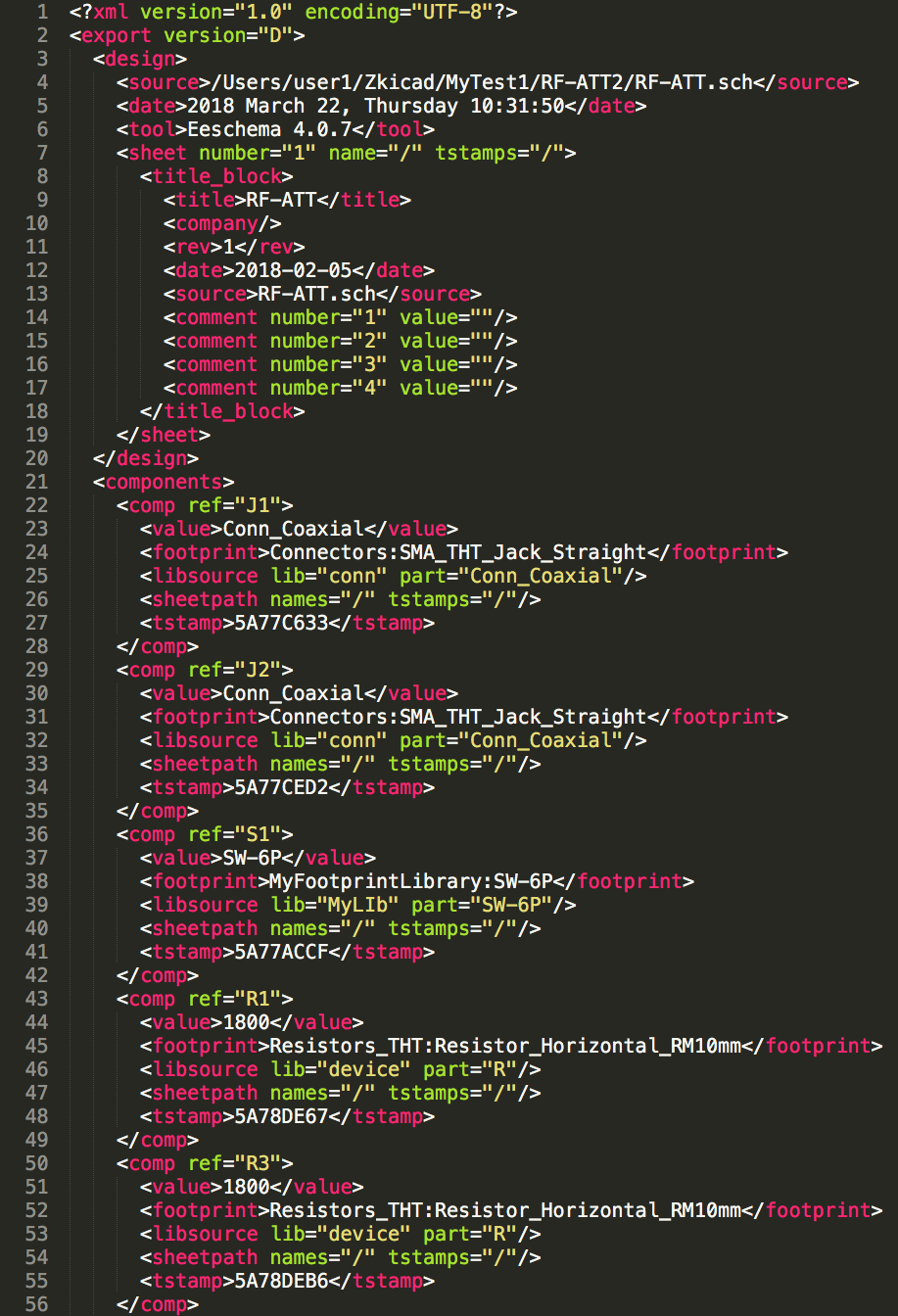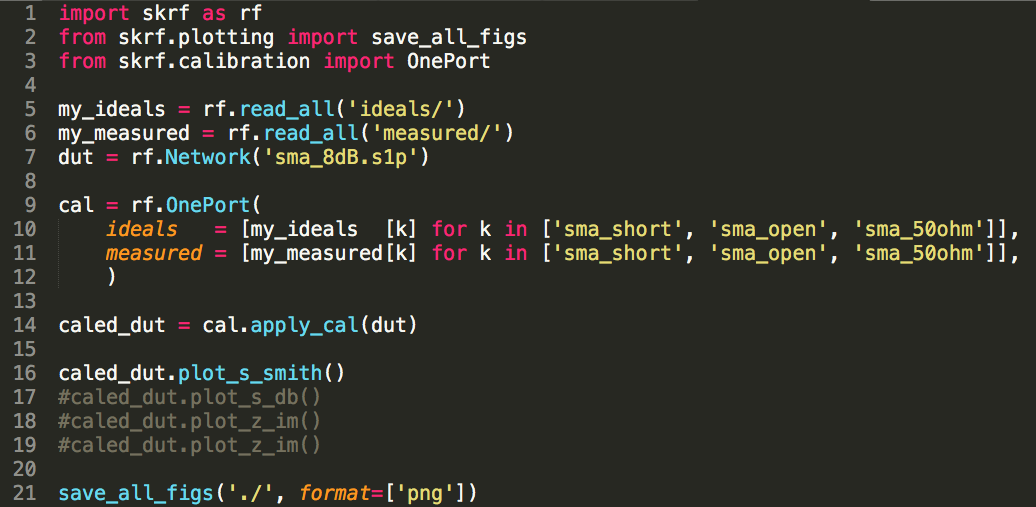
scikit-rfを用いて、1ポート校正がうまく出来ているのか、あまり自信がありません。
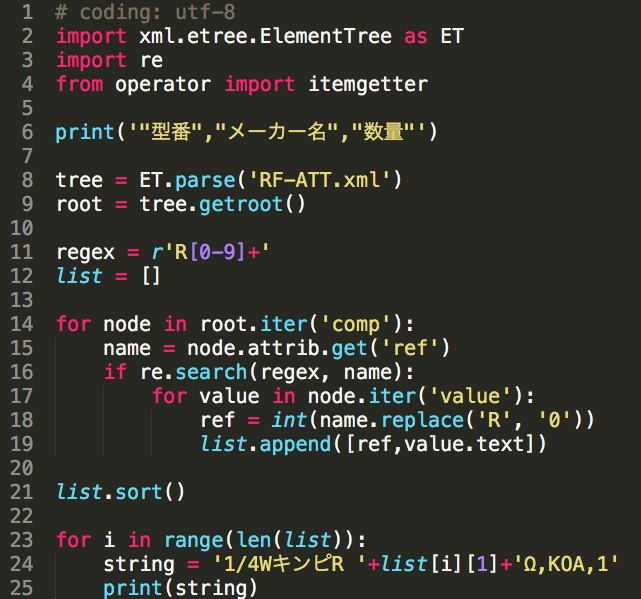
import skrf as rf
from skrf.plotting import save_all_figs
from skrf.calibration import OnePort
my_ideals = rf.read_all('ideals/')
my_measured = rf.read_all('measured/')
dut = rf.Network('sma_8dB.s1p')
cal = rf.OnePort(
ideals = [my_ideals [k] for k in ['sma_short', 'sma_open', 'sma_50ohm']],
measured = [my_measured[k] for k in ['sma_short', 'sma_open', 'sma_50ohm']],
)
caled_dut = cal.apply_cal(dut)
caled_dut.plot_s_smith()
#caled_dut.plot_s_db()
#caled_dut.plot_z_im()
#caled_dut.plot_z_im()
save_all_figs('./', format=['png'])
$ ls -l ./ideals/ ./measured/ ./ideals/: total 24 -rw-r--r-- 1 user1 staff 869 Mar 31 20:02 sma_50ohm.s1p -rw-r--r-- 1 user1 staff 869 Mar 31 20:04 sma_open.s1p -rw-r--r-- 1 user1 staff 970 Mar 31 20:07 sma_short.s1p ./measured/: total 32 -rw-r--r-- 1 user1 staff 2686 Mar 31 20:13 sma_50ohm.s1p -rw-r--r-- 1 user1 staff 2450 Mar 31 20:13 sma_8dB.s1p -rw-r--r-- 1 user1 staff 2426 Mar 31 20:13 sma_open.s1p -rw-r--r-- 1 user1 staff 2337 Mar 31 20:13 sma_short.s1p
$ head ./ideals/sma_50ohm.s1p ./measured/sma_50ohm.s1p ==> ./ideals/sma_50ohm.s1p <== # MHz S RI R 50 0 0 0 0.3 0 0 0.6 0 0 0.9 0 0 1.2 0 0 1.5 0 0 1.8 0 0 2.1 0 0 2.4 0 0 ==> ./measured/sma_50ohm.s1p <== # MHz S RI R 50 0 0.00701499 0.00504031 0.3 0.00701499 0.00504031 0.6 0.00701499 0.00504031 0.9 0.00878989 0.0028871 1.2 0.00932459 0.00274434 1.5 0.00956452 0.00248623 1.8 0.01028 0.00211041 2.1 0.0100815 0.00206556 2.4 0.0127909 0.00148593
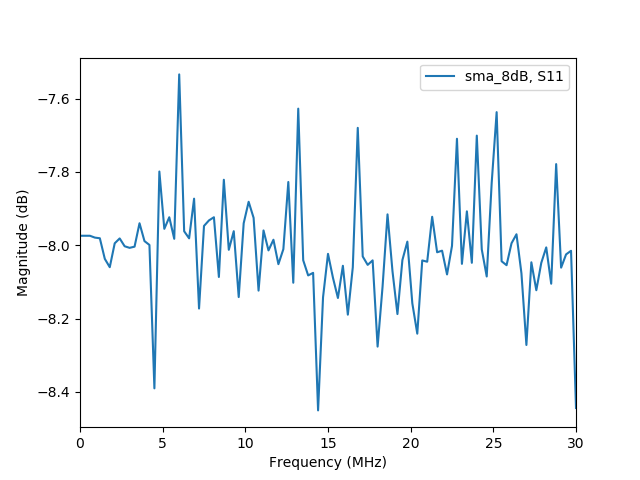

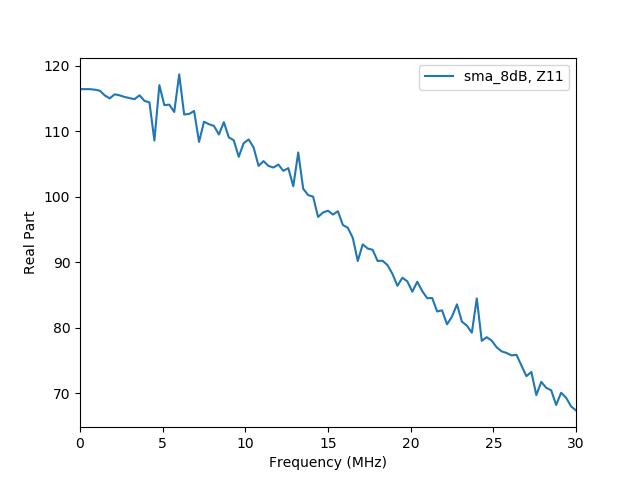
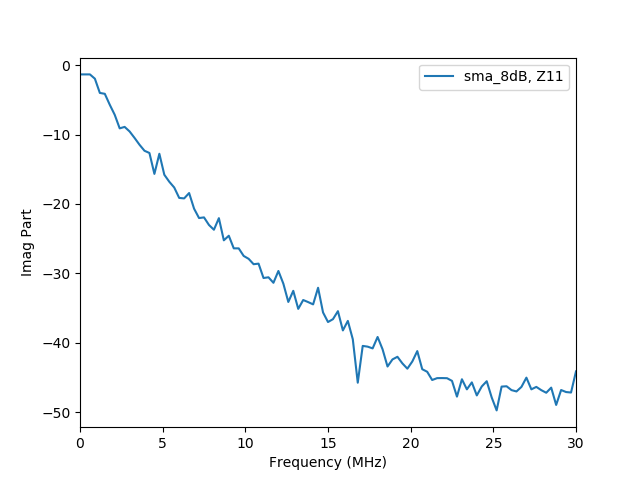
校正前より、良くなっているのでしょうか?